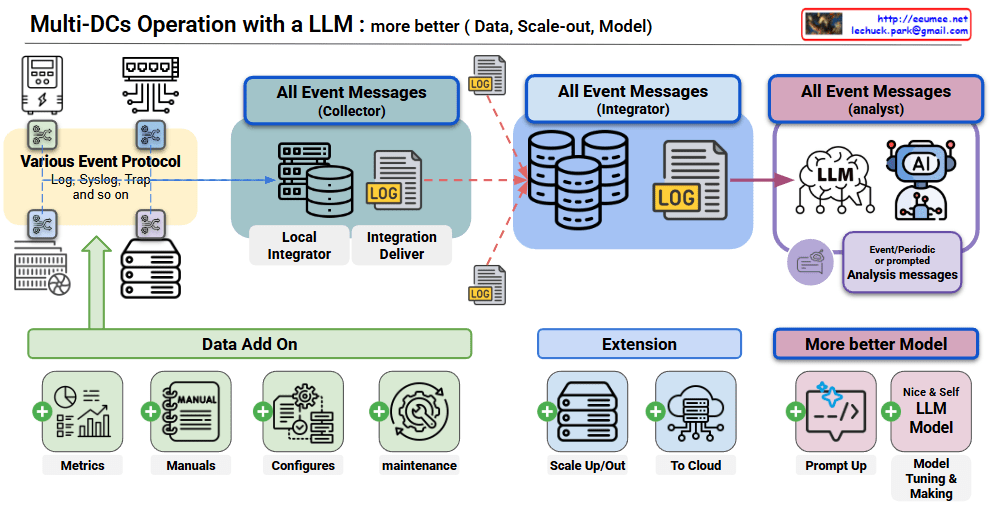
Someday Study
The Computing for the Fair Human Life.

Operational Performance Levels (Color-coded meanings):
Objective: keep <Green> higher than <Blue>
Objective: move <Green> to <Red>
1. Importance of Sequential Approach
2. Cost Efficiency Paradox
3. Dynamic Equilibrium Maintenance
This model visualizes the core principle of modern system operations: “Stability is the prerequisite for efficiency.” Rather than pursuing performance improvements alone, it presents strategic guidelines for achieving genuine operational efficiency through gradual and sustainable optimization built upon a solid foundation of stability.
The framework emphasizes that true operational excellence comes not from aggressive optimization, but from maintaining the optimal balance between risk mitigation and performance enhancement, ensuring long-term business value creation through sustainable operational practices.
With Claude
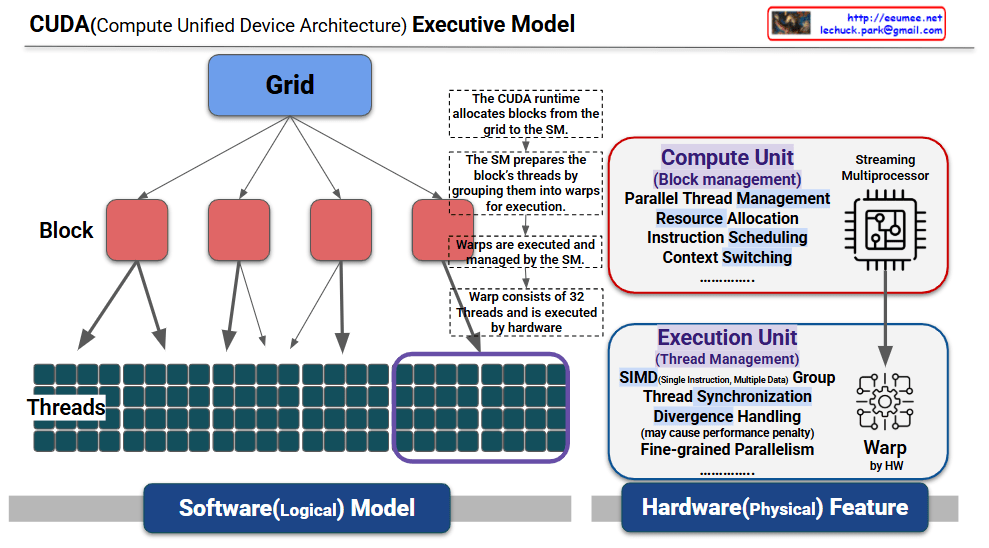
This is a structured explanation based on the provided CUDA (Compute Unified Device Architecture) execution model diagram. This diagram visually represents the relationship between the software (logical model) and hardware (physical device) layers in CUDA, illustrating the parallel processing mechanism step by step. The explanation reflects the diagram’s annotations and structure.
<<<blocksPerGrid, threadsPerBlock>>>).threadIdx) and processes different data.if-else), sequential execution occurs, potentially causing a performance penalty, as noted in “Divergence Handling (may cause performance penalty).”This diagram illustrates the CUDA execution model by mapping the software layers (grid → block → threads) to the hardware (SM → warp). The CUDA runtime allocates blocks from the grid to the SM, the SM groups threads into warps for execution, and warps perform parallel computations using the SIMT model.
Work with Grok

This image shows a diagram of an Emergency Power System and the characteristics of each component.
At the top, the power grid is connected to servers/data centers, and three backup power options are presented in case of power supply interruption.
DR (Diesel Rotary) UPS: A special form of Dynamic UPS that provides uninterrupted power through flywheel energy storage technology.
Generators can operate long-term with fuel supply but have start-up delays, while Static UPS provides immediate power but only for short durations. Dynamic UPS (including DR UPS) is a hybrid solution that provides uninterrupted power through flywheel technology while enabling long-term operation when combined with diesel engines. In actual operations, it’s common to use these systems in combination, considering the advantages and disadvantages of each system.
With Claude

This diagram illustrates the Memory Bound phenomenon in computer systems.
Memory bound refers to a situation where the overall processing speed of a computer is limited not by the computational power of the CPU, but by the rate at which data can be read from memory.
The Processing Elements (PEs) on the right have high computational capabilities, but the overall system performance is constrained by the slower speed of data retrieval from memory.
Memory bound occurs when system performance is limited by memory access speed rather than computational power. This bottleneck commonly arises from large data transfers, cache misses, and memory bandwidth constraints. It represents a critical challenge in modern computing, particularly affecting GPU computing and AI/ML workloads where processing units often wait for data rather than performing calculations.
With Claude