Externals of Modular DC Infrastructure
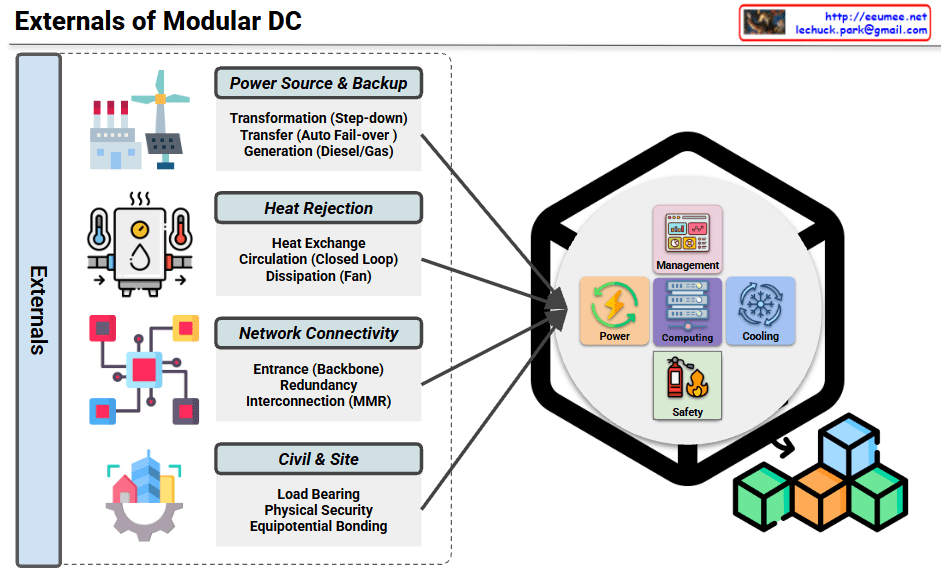
This diagram illustrates the external infrastructure systems that support a Modular Data Center (Modular DC).
Main Components
1. Power Source & Backup
- Transformation (Step-down transformer)
- Transfer switch (Auto Fail-over)
- Generation (Diesel/Gas generators)
Ensures stable power supply and emergency backup capabilities.
2. Heat Rejection
- Heat Exchange equipment
- Circulation system (Closed Loop)
- Dissipation system (Fan-based)
Cooling infrastructure that removes heat generated from the data center to the outside environment.
3. Network Connectivity
- Entrance (Backbone connection)
- Redundancy configuration
- Interconnection (MMR – Meet Me Room)
Provides connectivity and telecommunication infrastructure with external networks.
4. Civil & Site
- Load Bearing structures
- Physical Security facilities
- Equipotential Bonding
Handles building foundation and physical security requirements.
Internal Management Systems
The module integrates the following management elements:
- Management: Integrated control system
- Power: Power management
- Computing: Computing resource management
- Cooling: Cooling system control
- Safety: Safety management
Summary
Modular data centers require four critical external infrastructure systems: power supply with backup generation, heat rejection for thermal management, network connectivity for communications, and civil/site infrastructure for physical foundation and security. These external systems work together to support the internal management components (power, computing, cooling, and safety) within the modular unit. This architecture enables rapid deployment while maintaining enterprise-grade reliability and scalability.
#ModularDataCenter #DataCenterInfrastructure #DCInfrastructure #EdgeComputing #HybridIT #DataCenterDesign #CriticalInfrastructure #PowerBackup #CoolingSystem #NetworkRedundancy #PhysicalSecurity #ModularDC #DataCenterSolutions #ITInfrastructure #EnterpriseIT
With Claude