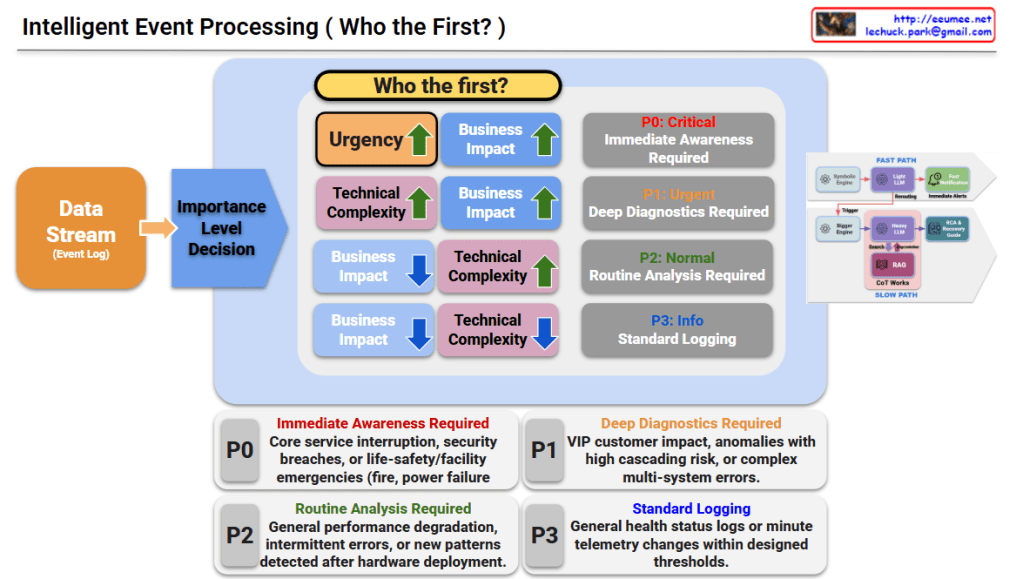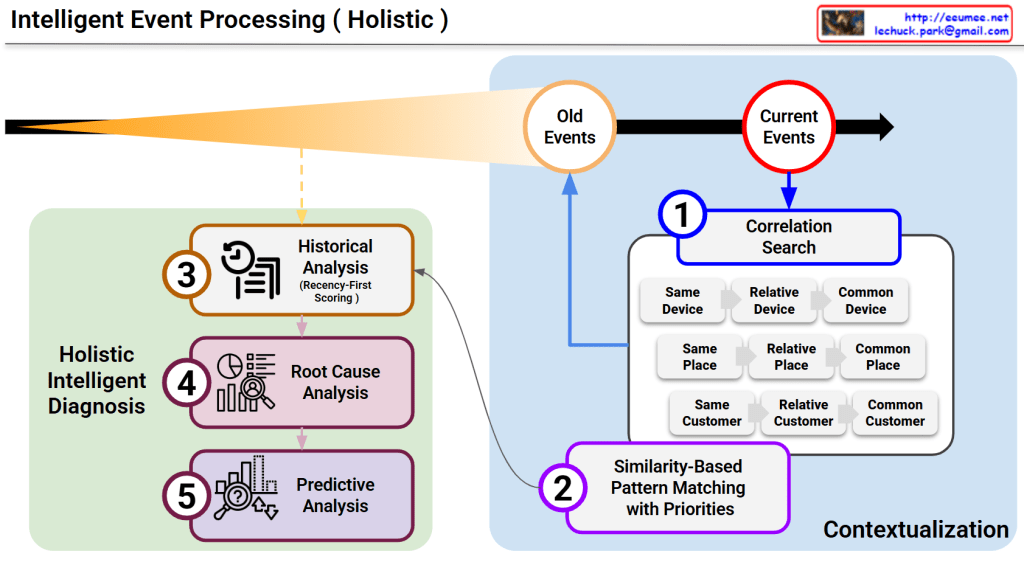
This diagram illustrates a sophisticated framework for Intelligent Event Processing, designed to provide a comprehensive, multi-layered diagnosis of system events. It moves beyond simple alerts by integrating historical context, spatial correlations, and future projections.
1. The Principle of Recency-First Scoring (Top Section)
The orange cone expanding toward the Current Events represents the Time-Decay or Recency-First Scoring model.
- Weighted Importance: While “Old Events” are maintained for context, the system assigns significantly higher weight to the most recent data.
- Sensitivity: This ensures the AI remains highly sensitive to emerging trends and immediate anomalies while naturally phasing out obsolete patterns.
2. Multi-Dimensional Correlation Search (Box 1)
When a current event is detected, the system immediately executes a Correlation Search across three primary dimensions to establish a spatial and logical context:
- Device Context: Investigates if the issue is isolated to the same device, related devices, or common device types.
- Spatial Context (Place): Analyzes if the event is tied to a specific location, a relative area (e.g., the same rack), or a common facility environment.
- Customer Context: Checks for patterns across the same customer, relative accounts, or common customer profiles.
3. Similarity-Based Pattern Matching (Box 2)
By combining the results of the Correlation Search with the library of “Old Events,” the system performs Pattern Matching with Priorities.
- This step identifies historical precedents that most closely resemble the current event’s “fingerprint.”
- It functions similarly to Case-Based Reasoning (CBR), leveraging past solutions to address present challenges.
4. Holistic Intelligent Diagnosis (Green Box)
This is the core engine where three distinct analytical disciplines converge to create an actionable output:
- ③ Historical Analysis: Utilizes the recency-weighted scores to understand the evolution of the current issue.
- ④ Root Cause Analysis (RCA): Drills down into the underlying triggers to identify the “why” behind the event.
- ⑤ Predictive Analysis: Projects the likely future trajectory of the event, allowing for proactive rather than reactive management.
Summary
For the platform, this diagram serves as the “brain” of the operation. It demonstrates how the agent doesn’t just see a single data point, but rather a “Holistic” picture that connects the dots across time, space, and causality.
#DataCenterOps #AI #EventProcessing #RootCauseAnalysis #PredictiveMaintenance #DataAnalytics #IntelligentDiagnosis #SystemMonitoring #TechInfrastructure
with Gemini