AI DC: The Chain Reaction from CAPEX to OPEX Risk
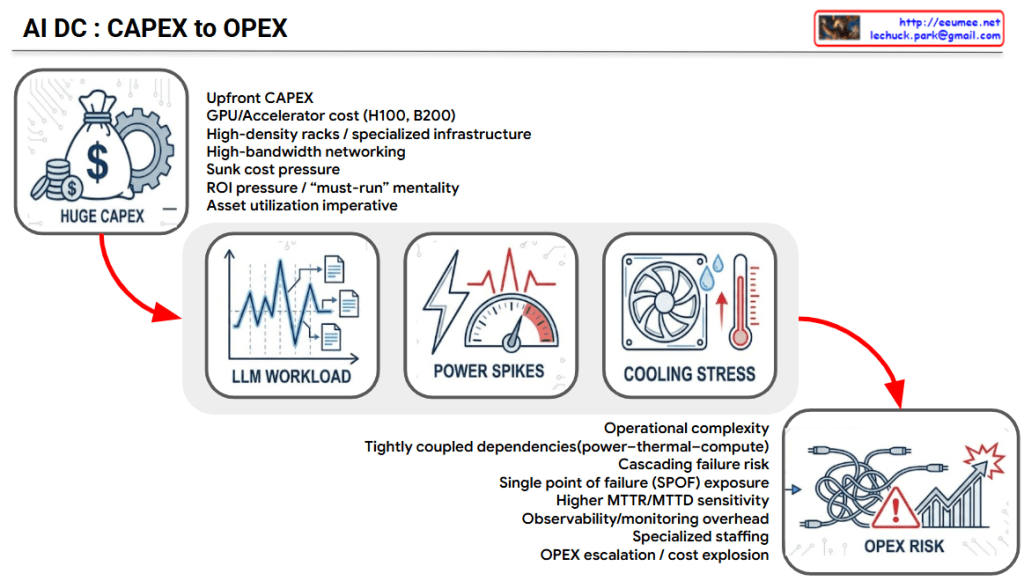
The provided image logically illustrates the sequential mechanism of how the massive initial capital expenditure (CAPEX) of an AI Data Center (AI DC) translates into complex operational risks and increased operating expenses (OPEX).
1. HUGE CAPEX (Massive Initial Investment)
- Context: Building an AI data center requires enormous capital expenditure (CAPEX) due to high-cost GPU servers, high-density racks, and specialized networking infrastructure.
- Flow: However, the challenge does not end with high initial costs. Driven by the following three factors, this massive infrastructure investment inevitably cascades into severe operational risks.
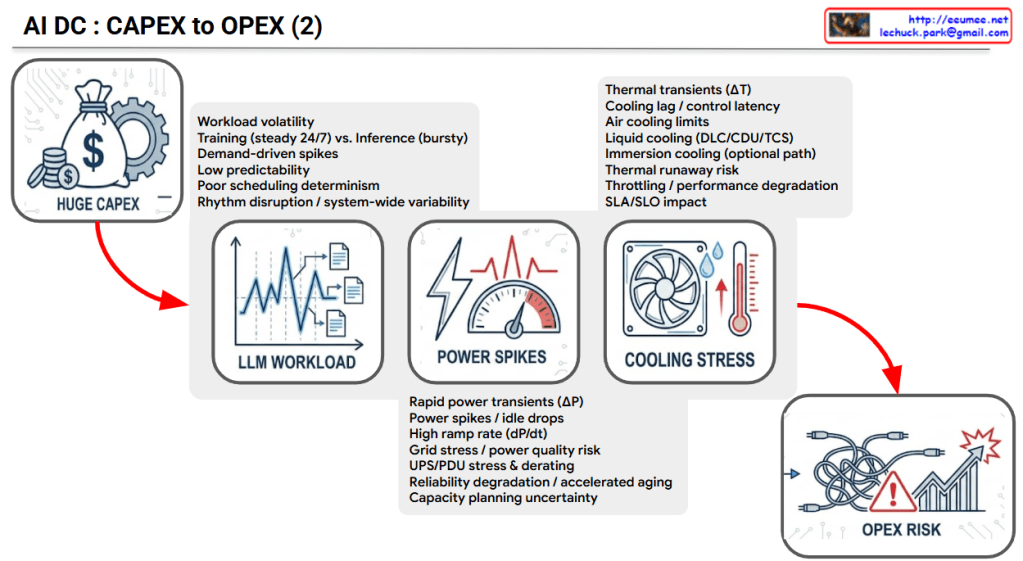
2. LLM WORKLOAD (The Root Cause)
- Characteristics: Unlike traditional IT workloads, AI (especially LLM) workloads are highly volatile and unpredictable.
- Key Factors: * The continuous, heavy load of Training (steady 24/7) mixed with the bursty, erratic nature of Inference.
- Demand-driven spikes and low predictability, which lead to poor scheduling determinism and system-wide rhythm disruption.
3. POWER SPIKES (Electrical Infrastructure Stress)
- Characteristics: The extreme volatility of LLM workloads causes sudden, extreme fluctuations in server power consumption.
- Key Factors:
- Rapid power transients (ΔP) and high ramp rates (dP/dt) create sudden power spikes and idle drops.
- These fluctuations cause significant grid stress, accelerate the aging of power distribution equipment (UPS/PDU stress & derating), degrade overall system reliability, and create major capacity planning uncertainty.
4. COOLING STRESS (Thermal System Stress)
- Characteristics: Sudden surges in power consumption immediately translate into rapid temperature increases (Thermal transients, ΔT).
- Key Factors:
- Cooling lag / control latency: There is an inevitable delay between the sudden heat generation and the cooling system’s physical response.
- Physical limits: Traditional air cooling hits its limits, forcing transitions to Liquid cooling (DLC/CDU) or Immersion cooling. Failure to manage this latency increases the risk of thermal runaway, triggers system throttling (performance degradation), and negatively impacts SLAs/SLOs.
5. OPEX RISK (The Final Operational Consequence)
- Context: The combination of unpredictable LLM workloads, power infrastructure stress, and cooling system limitations culminates in severe OPEX Risk.
- Conclusion: Ultimately, this chain reaction exponentially increases daily operational costs and uncertainties—ranging from accelerated equipment replacement costs and higher power bills (due to degraded PUE) to massive expenses related to frequent incident responses and infrastructure instability.
Summary:
The slide delivers a powerful message: While the physical construction of an AI data center is highly expensive (CAPEX), the true danger lies in the unique volatility of AI workloads. This volatility triggers extreme power (ΔP) and thermal (ΔT) spikes. If these physical transients are not strictly managed, the operational costs and risks (OPEX) will spiral completely out of control.
#AIDataCenter #AIDC #CAPEX #OPEX #LLMWorkload #PowerSpikes #CoolingStress #LiquidCooling #ThermalManagement #DataCenterInfrastructure #GPUInfrastructure #OPEXRisk
With Gemini