
This illustration contrasts an old approach of endlessly adding more GPU servers, burning money for little gain, with a new era where AI-driven optimization of software, network, cooling and power delivers smarter GPUs and a much better ROI.
The Computing for the Fair Human Life.
This illustration contrasts an old approach of endlessly adding more GPU servers, burning money for little gain, with a new era where AI-driven optimization of software, network, cooling and power delivers smarter GPUs and a much better ROI.
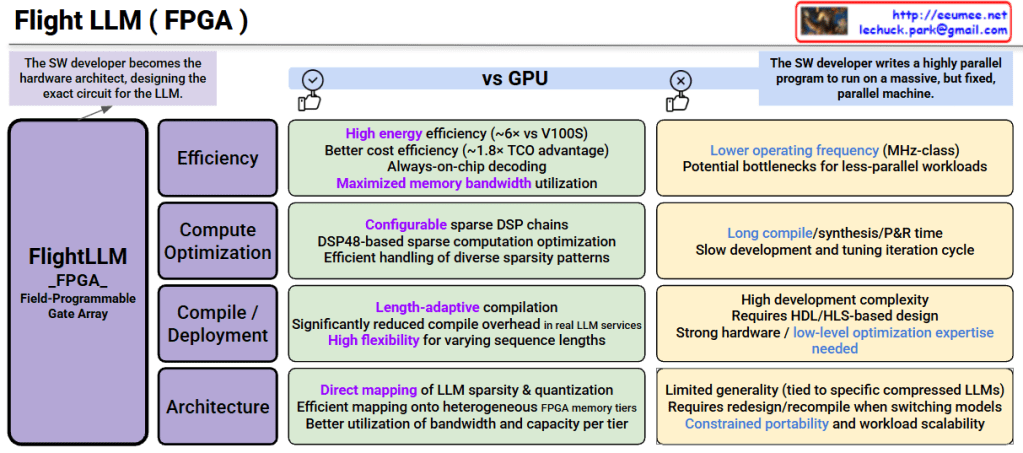
This image is a technical document comparing “FlightLLM,” an FPGA-based LLM (Large Language Model) accelerator, with GPUs.
Core Concept: An LLM inference accelerator utilizing Field-Programmable Gate Array, where SW developers become hardware architects, designing the exact circuit for the LLM.
1. Efficiency
2. Compute Optimization
3. Compile/Deployment
4. Architecture
1. Operating Frequency
2. Development Time
3. Development Complexity
4. Portability Constraints
FPGAs offer superior energy and cost efficiency for specific LLM workloads but require significantly higher development expertise and have lower flexibility compared to GPUs. They excel in massive, fixed parallel workloads but struggle with rapid model iteration and portability.
FlightLLM leverages FPGAs to achieve 6x energy efficiency and 1.8x cost advantage over GPUs through direct hardware mapping of LLM operations. However, this comes at the cost of high development complexity, requiring HDL/HLS expertise and long compilation times. FPGAs are ideal for production deployments of specific LLM models where efficiency outweighs the need for flexibility and rapid iteration.
#FPGA #LLM #AIAccelerator #FlightLLM #HardwareOptimization #EnergyEfficiency #MLInference #CustomHardware #AIChips #DeepLearningHardware
With Claude

This image illustrates the structural differences between UPS (Uninterruptible Power System) and ESS (Energy Storage System), emphasizing the advanced safety technologies required for ESS due to its “High Power, High Risk” nature.
This section contrasts the purpose and scale of the two systems, highlighting why ESS requires stricter safety measures.
Since standard UPS technologies (indicated in gray text) are insufficient for ESS, the image outlines four critical technological upgrades (indicated in bold text).
① Battery Management System (BMS)
② Thermal Management System
③ Fire Detection & Suppression
④ Physical/Structural Safety
#ESS #UPS #BatterySafety #BMS #ThermalManagement #EnergyStorage #FireSafety #Engineering #TechTrends #OffGasDetection
WIth Gemini
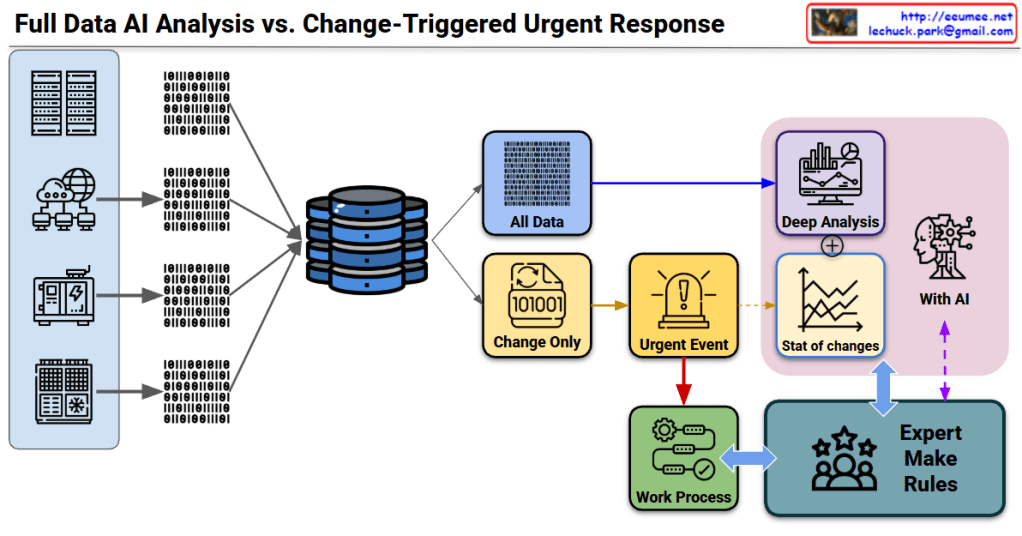
This diagram illustrates a system architecture comparing two core strategies for data processing.
[Data Collection]
↓
[Path Bifurcation]
├─→ [All Data] → [Deep Analysis] ─┐
│ ├→ [AI Statistical Analysis]
└─→ [Change Only] → [Urgent Event]─┘
↓
[Work Process] ↔ [Expert Make Rules]
↑_____________↓
(Feedback loop with AI)
This system is an architecture optimized for environments where real-time response is essential while expert judgment remains critical (manufacturing, infrastructure operations, security monitoring, etc.).
#DataArchitecture #AIAnalysis #EventDrivenArchitecture #RealTimeMonitoring #HybridProcessing #ExpertSystems #ChangeDetection #UrgentResponse #IndustrialAI #SmartMonitoring #DataProcessing #AIHumanCollaboration #PredictiveMaintenance #IoTArchitecture #EnterpriseAI
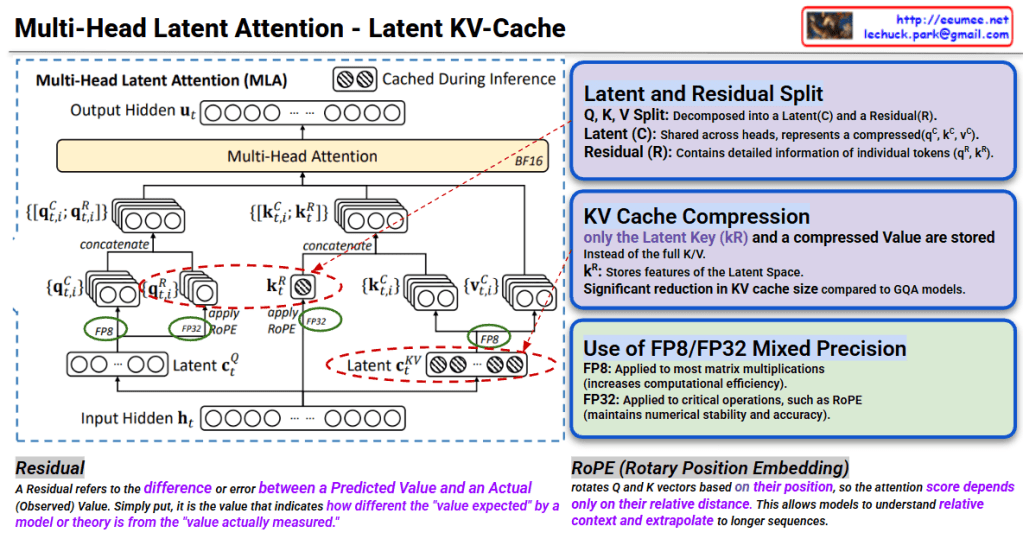
This image explains the Multi-Head Latent Attention (MLA) mechanism and Latent KV-Cache technique for efficient inference in transformer models.
Q, K, V are decomposed into two components:
Instead of traditional approach, stores only in compressed form:
This technique represents a cutting-edge optimization for LLM inference that dramatically reduces memory footprint by storing only compressed latent representations in the KV cache while maintaining model quality. The combination of latent-residual decomposition and mixed precision (FP8/FP32) enables both faster computation and longer context handling. RoPE further enhances the model’s ability to understand relative positions in extended sequences.
#MultiHeadAttention #LatentAttention #KVCache #TransformerOptimization #LLMInference #ModelCompression #MixedPrecision #FP8 #RoPE #EfficientAI #DeepLearning #AttentionMechanism #ModelAcceleration #AIOptimization #NeuralNetworks
With Cluade
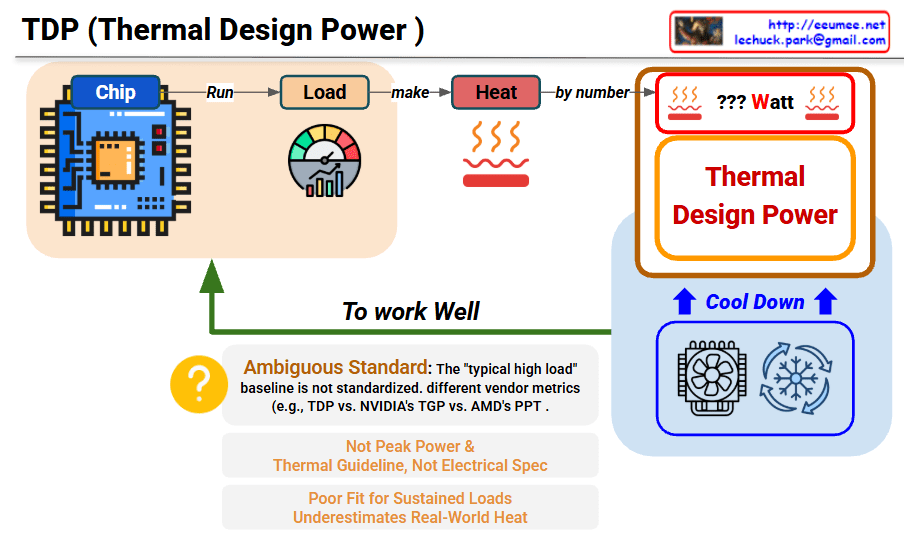
This image explains the concept and limitations of TDP (Thermal Design Power).
Chip → Run Load → Generate Heat → TDP Measurement
TDP is a thermal guideline for cooling system design, not an accurate measure of actual power consumption or heat generation. Different manufacturers use inconsistent standards (TDP/TGP/PPT), making comparisons difficult. It underestimates real-world heat and peak power, serving only as a reference point rather than a precise specification.
#TDP #ThermalDesignPower #CPUCooling #PCHardware #ThermalManagement #ComputerCooling #ProcessorSpecs #HardwareEducation #TechExplained #CoolingSystem #PowerConsumption #PCBuilding #TechSpecs #HeatDissipation #HardwareLimitations
With Claude

