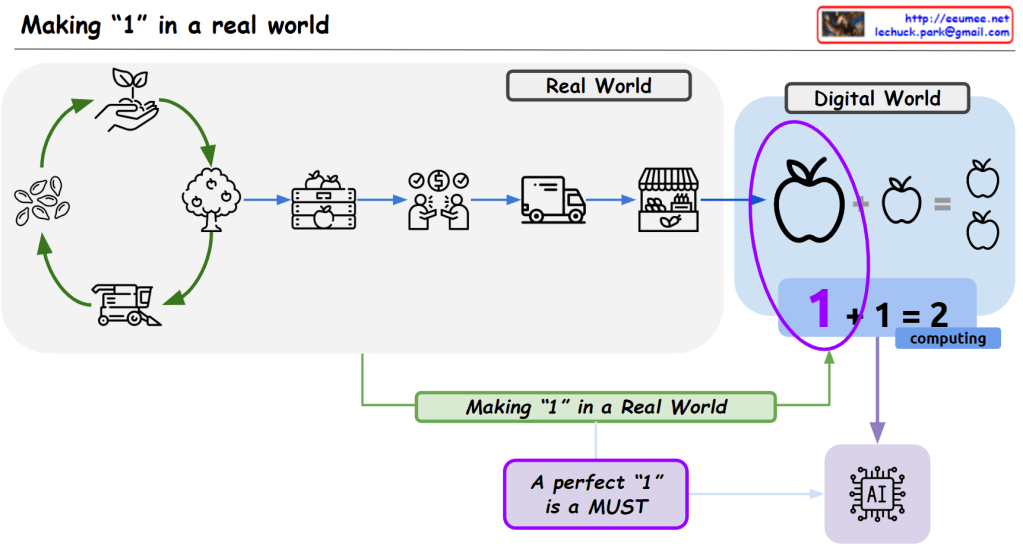
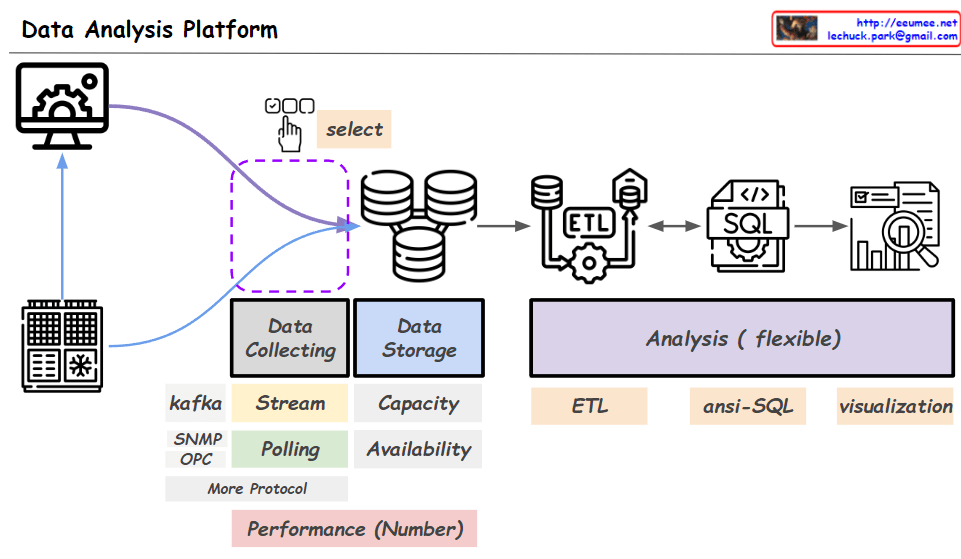
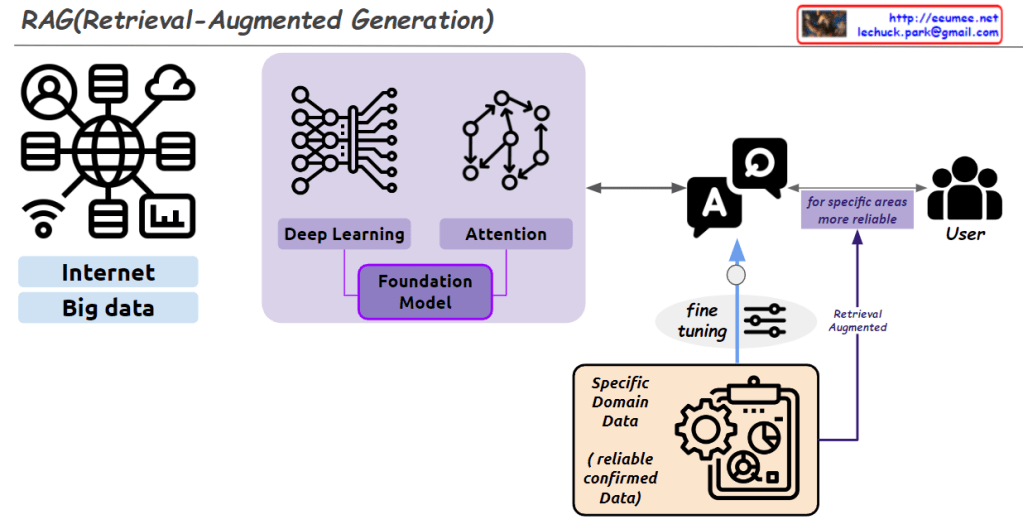
From Claude with some prompting
This image conceptually illustrates various factors that can affect the performance of DC data collection. The main components include the facility generating the data, the facility network, PLC/DDC converters, an integration network, and the final collection/analysis system.
Factors that can impact data collection performance include the data generation rate, CPU performance, bandwidth limitations of the network medium, network topology, protocols used (such as TCP/IP and SNMP), input/output processing performance, and program logic.
The diagram systematically outlines the overall flow of the DC data collection process and the performance considerations at each stage. It covers elements like the facility, network infrastructure, data conversion, integration, and final collection/analysis.
By mapping out these components and potential bottlenecks, the image can aid in the design and optimization of data collection systems. It provides a comprehensive overview of the elements that need to be accounted for to ensure efficient data gathering performance.