Intelligent Event Processing System Overview
This architecture illustrates how a system intelligently prioritizes data streams (event logs) and selects the most efficient processing path—either for speed or for depth of analysis.
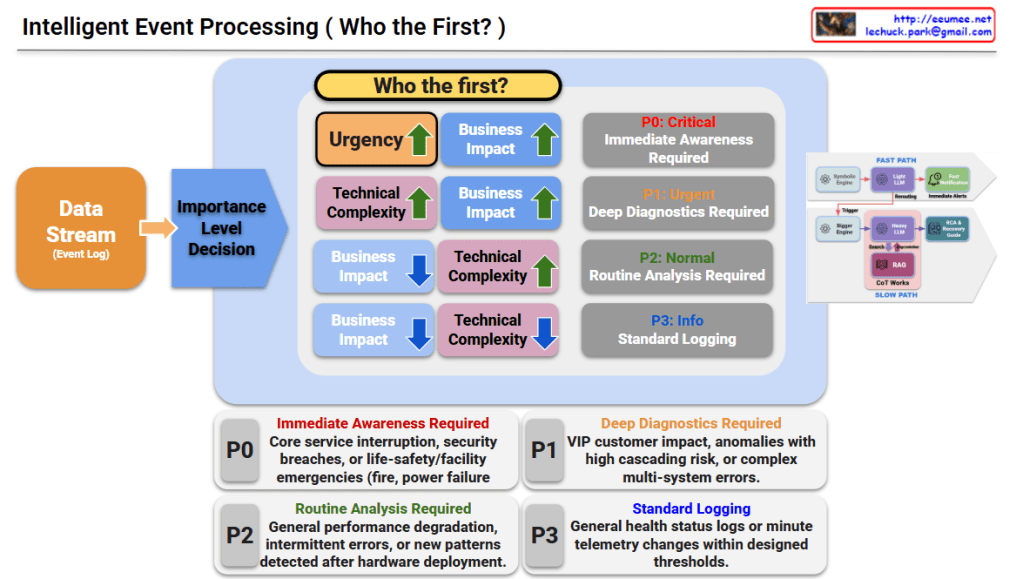
1. Importance Level Decision (Who the First?)
Events are categorized into four priority levels ($P0$ to $P3$) based on Urgency, Business Impact, and Technical Complexity.
- P0: Critical (Immediate Awareness Required)
- Criteria: High Urgency + High Business Impact.
- Scope: Core service interruptions, security breaches, or life-safety/facility emergencies (e.g., fire, power failure).
- P1: Urgent (Deep Diagnostics Required)
- Criteria: High Technical Complexity + High Business Impact.
- Scope: VIP customer impact, anomalies with high cascading risk, or complex multi-system errors.
- P2: Normal (Routine Analysis Required)
- Criteria: High Technical Complexity + Low Business Impact.
- Scope: General performance degradation, intermittent errors, or new patterns detected after hardware deployment.
- P3: Info (Standard Logging)
- Criteria: Low Technical Complexity + Low Business Impact.
- Scope: General health status logs or minute telemetry changes within designed thresholds.
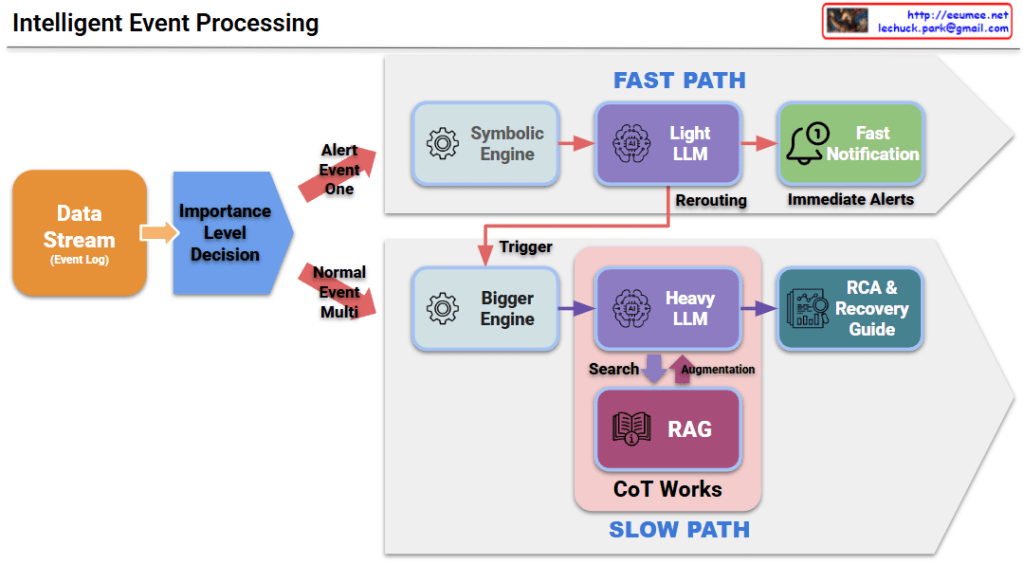
2. Processing Paths: Fast Path vs. Slow Path
The system routes events through two different AI-driven pipelines to balance speed and accuracy.
A. Fast Path (Optimized for P0)
- Workflow: Symbolic Engine → Light LLM → Fast Notification.
- Goal: Minimizes latency to provide Immediate Alerts for critical issues where every second counts.
B. Slow Path (Optimized for P1 & P2)
- Workflow: Bigger Engine → Heavy LLM + RAG (Retrieval-Augmented Generation) + CoT (Chain of Thought).
- Goal: Delivers high-quality Root Cause Analysis (RCA) and detailed Recovery Guides for complex problems requiring deep reasoning.
Summary
- The system automatically prioritizes event logs into four levels (P0–P3) based on their urgency, business impact, and technical complexity.
- It bifurcates processing into a Fast Path using light models for instant alerting and a Slow Path using heavy LLMs/RAG for deep diagnostics.
- This dual-track approach maximizes operational efficiency by ensuring critical failures are reported instantly while complex issues receive thorough AI-driven analysis.
#AIOps #IntelligentEventProcessing #LLM #RAG #SystemMonitoring #IncidentResponse #ITAutomation #CloudOperations #RootCauseAnalysis
With Gemini