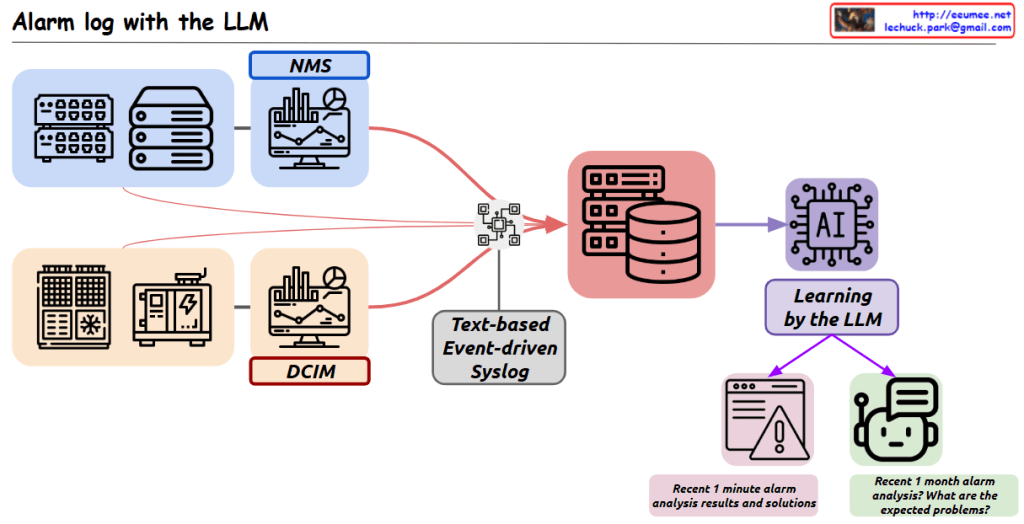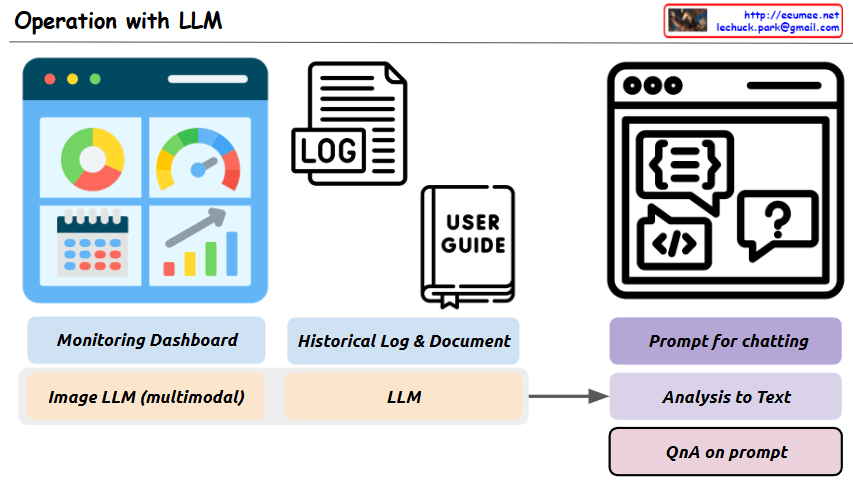
This image is a diagram titled “Operation with LLM,” showing a system architecture that integrates Large Language Models (LLMs) with existing operational technologies.
The main purpose of this system is to more efficiently analyze and solve various operational data and situations using LLMs.
Key components and functions:
- Top Left: “Monitoring Dashboard” – Provides an environment where LLMs can interpret image data collected from monitoring screens.
- Top Center: “Historical Log & Document” – LLMs analyze system log files and organize related processes from user manuals.
- Top Right: “Prompt for chatting” – An interface for interacting with LLMs through appropriate prompts.
- Bottom Left: “Image LLM (multimodal)” – Represents multimodal LLM functionality for interpreting images from monitoring screens.
- Bottom Center: “LLM” – The core language model component that processes text-based logs and documents.
- Bottom Right:
- “Analysis to Text” – LLMs analyze various input sources and convert them to text
- “QnA on prompt” – Users can ask questions about problem situations, and LLMs provide answers
This system aims to build an integrated operational environment where problems occurring in operational settings can be easily analyzed through LLM prompting and efficiently solved through a question-answer format.
With Claude