From Claude with some prompting
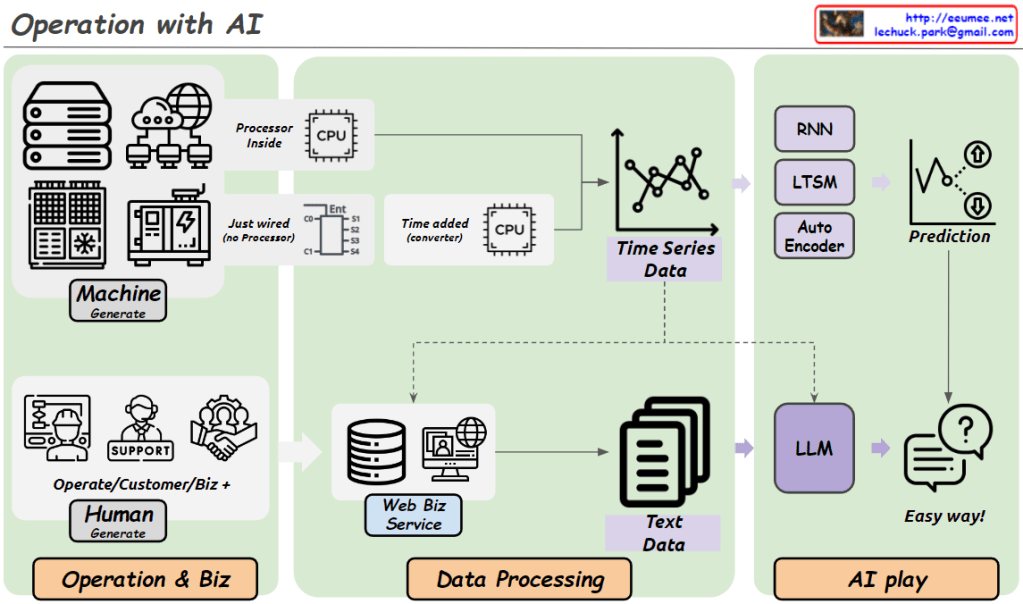
This diagram illustrates an integrated approach to modern operational management. The system is divided into three main components: data generation, data processing, and AI application.
The Operation & Biz section shows two primary data sources. First, there’s metric data automatically generated by machines such as servers and network equipment. Second, there’s textual data created by human operators and customer service representatives, primarily through web portals.
These collected data streams then move to the central Data Processing stage. Here, metric data is processed through CPUs and converted into time series data, while textual data is structured via web business services.
Finally, in the AI play stage, different AI models are applied based on data types. For time series data, models like RNN, LSTM, and Auto Encoder are used for predictive analytics. Textual data is processed through a Large Language Model (LLM) to extract insights.
This integrated system effectively utilizes data from various sources to improve operational efficiency, support data-driven decision-making, and enable advanced analysis and prediction through AI. Ultimately, it facilitates easy and effective management even in complex operational environments.
The image emphasizes how different types of data – machine-generated metrics and human-generated text – are processed and analyzed using appropriate AI techniques, all from the perspective of operational management.