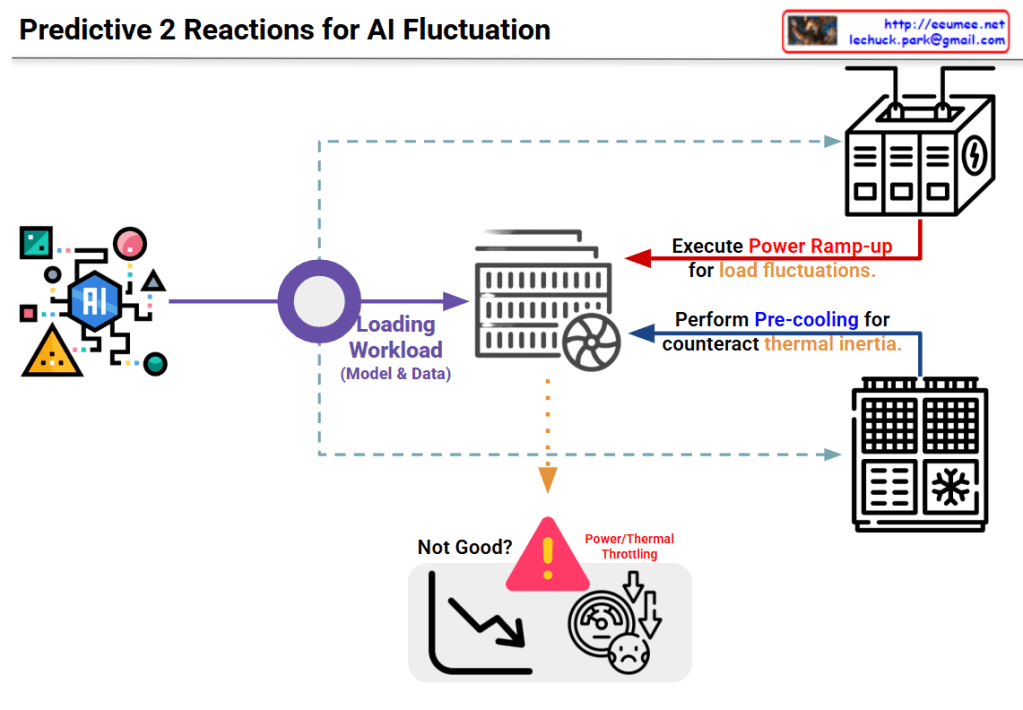
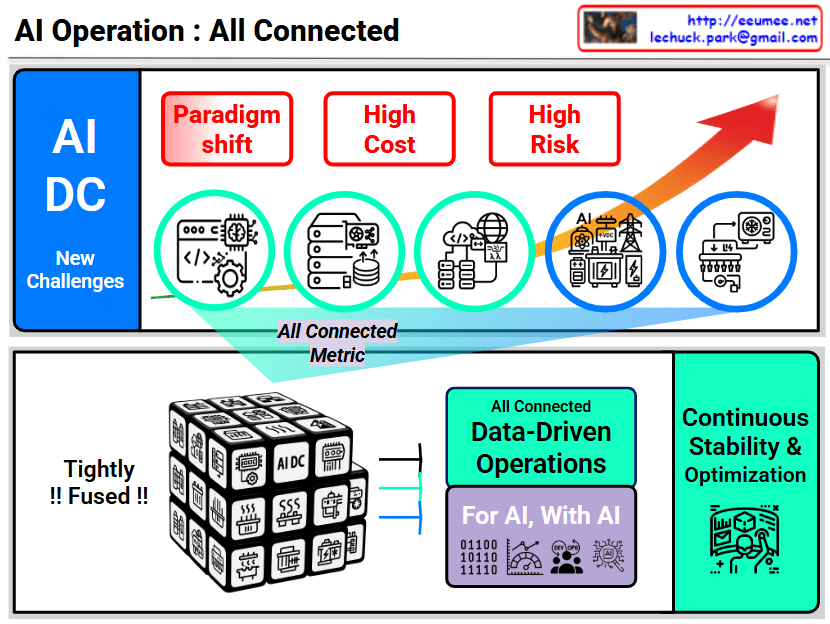
End-to-End AI Factory Optimization: Bridging Infrastructure and Business Value
This diagram outlines a comprehensive framework for optimizing an “AI Factory”—a modern data center dedicated to AI workloads. The core message is that optimizing AI performance and cost requires a holistic view that connects physical infrastructure realities directly to high-level business Service Level Agreements (SLAs).
Here is a breakdown of the three main pillars of this framework:
1. The AI Factory (Infrastructure Foundation)
On the far left, we see the AI Factory itself. This represents the converged physical infrastructure required to run massive AI models (indicated by the neural network icons).
It emphasizes that the critical hardware components—GPUs (Compute), Networking, Power, and Cooling—cannot be managed in silos. They are marked as “ULTRA CONNECTED,” meaning the behavior of one directly impacts the others (e.g., intense GPU activity spikes power demand and generates immediate heat, requiring instant cooling response).
2. Ultra Data Quality (The Intelligence Layer)
In the center, the diagram highlights the necessity of Ultra Data Quality. To optimize such a complex, interconnected system, standard logging isn’t enough. The telemetry data collected from the infrastructure must meet three critical criteria:
- Ultra Precision & Resolution: Capturing minute details of operations.
- Ultra Time-Sync: The ability to perfectly synchronize timestamps across different hardware types (e.g., nanosecond-level GPU events vs. millisecond-level cooling events) to understand cause-and-effect relationships accurately.
3. Cost & SLA vs. Usage+Performance (The Value Realization)
The right section is the most critical, showing the direct mapping between physical operational metrics (Usage+Performance) and business outcomes (Cost & SLA). It argues that physical stability directly dictates business success:
- TOKEN (Output/Revenue) ↔ Clock Consistency: To maintain a steady stream of AI output (tokens), the GPU clock speeds must remain consistent and stable without fluctuating.
- FLOPS (Peak Compute Power) ↔ Zero Throttling Events: Achieving maximum floating-point operations per second requires eliminating “throttling”—performance downgrades caused by overheating or power constraints.
- Watt (Operational Cost) ↔ Power Draw vs TDP: Managing operational expenses (electricity bills) requires optimizing the actual power draw relative to the hardware’s Thermal Design Power (TDP) limits.
- PUE (Data Center Efficiency) ↔ Thermal Headroom: The overall Power Usage Effectiveness of the facility depends on optimizing “thermal headroom”—managing how close the cooling systems run to their limits without wasting energy.
This diagram illustrates that optimizing an AI business isn’t just about better code or faster chips; it requires an end-to-end approach where the physical realities of power, cooling, and hardware are tightly integrated with data analytics to ensure performance promises (SLAs) are met cost-effectively.
#AIFactory #DataCenterOptimization #AIInfrastructure #GPUComputing #SLAmanagement #EnergyEfficiency #PUE #Operations #TechInnovation #ArtificialIntelligence