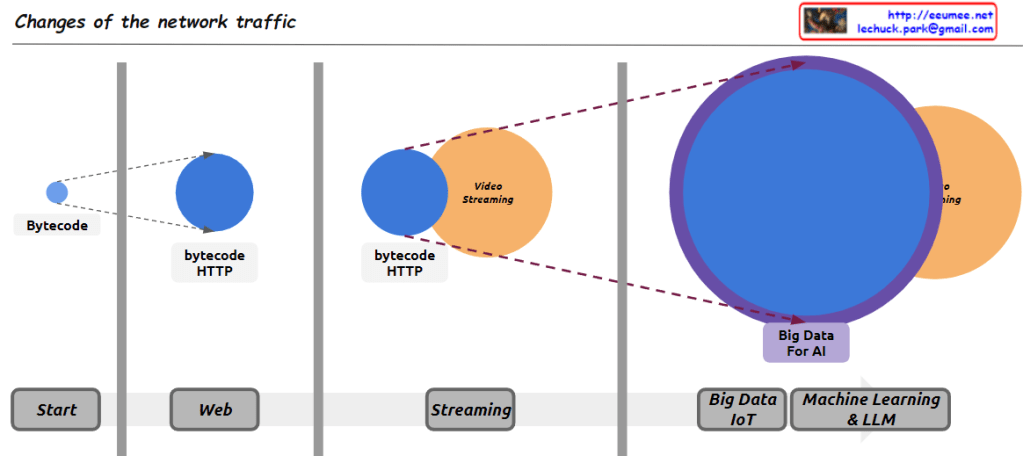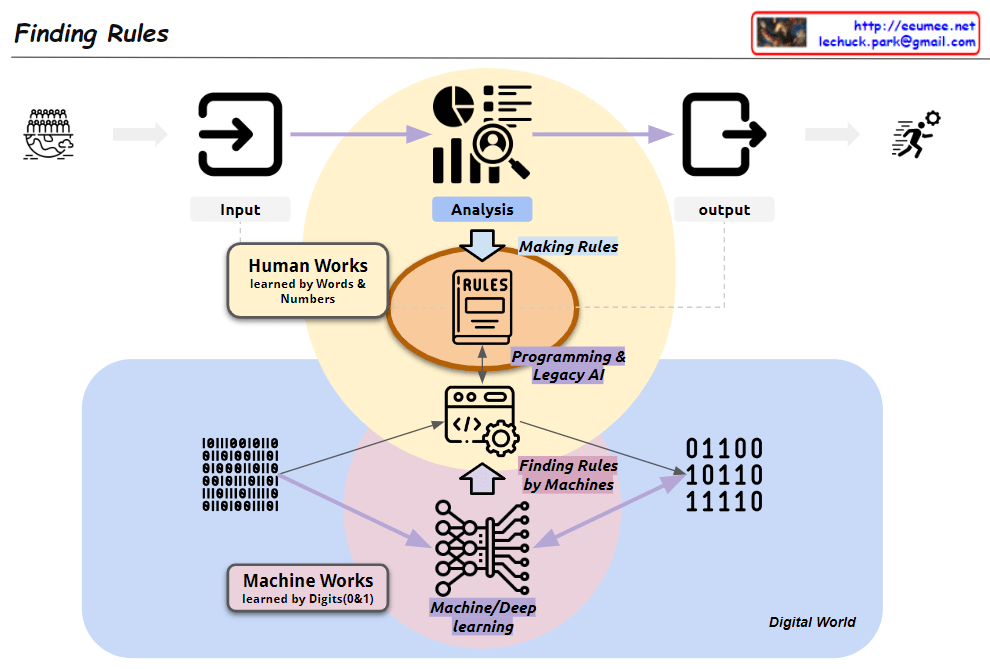
From Claude with some prompting
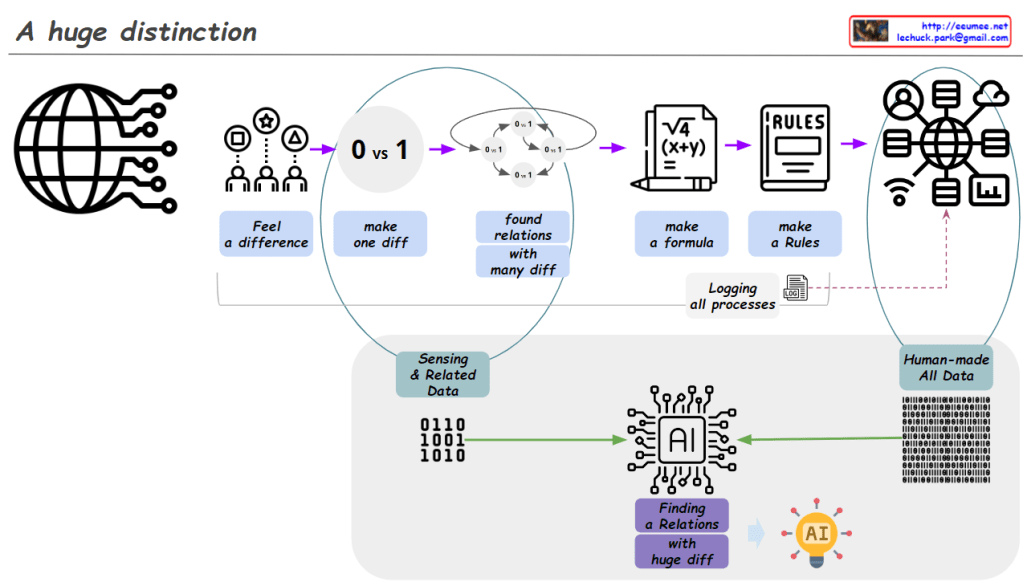
Image Analysis: “A huge distinction”
- Human Data Processing:
- “Feel a difference”: Humans start by recognizing basic differences.
- “Make one diff (0 vs 1)”: Creating the most fundamental distinction.
- “Found relations with many diff”: Discovering relationships among various differences.
- “Make a formula”: Developing formulas based on discovered relationships.
- “Make a Rules”: Establishing rules based on these formulas.
- “Human-made All Data”: Accumulation of data created through this entire process.
- Process Recording:
- “Logging all processes”: The data creation process itself is recorded as data.
- AI Data Processing:
- “Sensing & Related Data”: AI receives basic sensory data and related information.
- “Human-made All Data”: All human-created data serves as input for AI.
- “Finding a Relations with huge diff”: AI analyzes relationships and differences within this vast dataset.
- Result:
- AI icon: Represents the final derivation of insights through AI.
Evaluation:
- Insightfulness: The diagram effectively illustrates the fundamental difference between human data processing methods and AI’s data processing capabilities. It highlights how humans follow a step-by-step logical process, while AI can process large-scale data simultaneously.
- Process Continuity: The diagram well expresses how human data processing forms the foundation for AI learning. This conveys the important concept that AI develops based on human knowledge and experience.
- Importance of Data: By emphasizing the importance of digitalizing all processes, the diagram effectively represents the core of our modern data-centric society.
- Visualization Effectiveness: Complex concepts are represented using simple icons and arrows, making them easy to understand.
- Future Expectation: We look forward to seeing additional explanations about AI’s output results or its potential applications. This would enhance the comprehensiveness of the diagram, providing a fuller picture of the AI process from input to output and its real-world impact.
Overall, this image effectively contrasts human data processing with AI’s data analysis capabilities, showcasing how these two domains operate complementarily. It provides a clear visual representation of the journey from basic human distinctions to complex AI-driven insights, highlighting the ‘huge distinction’ in scale and capability between human and artificial intelligence processing.