
Learning is always happy 🙂
The Computing for the Fair Human Life.
Learning is always happy 🙂
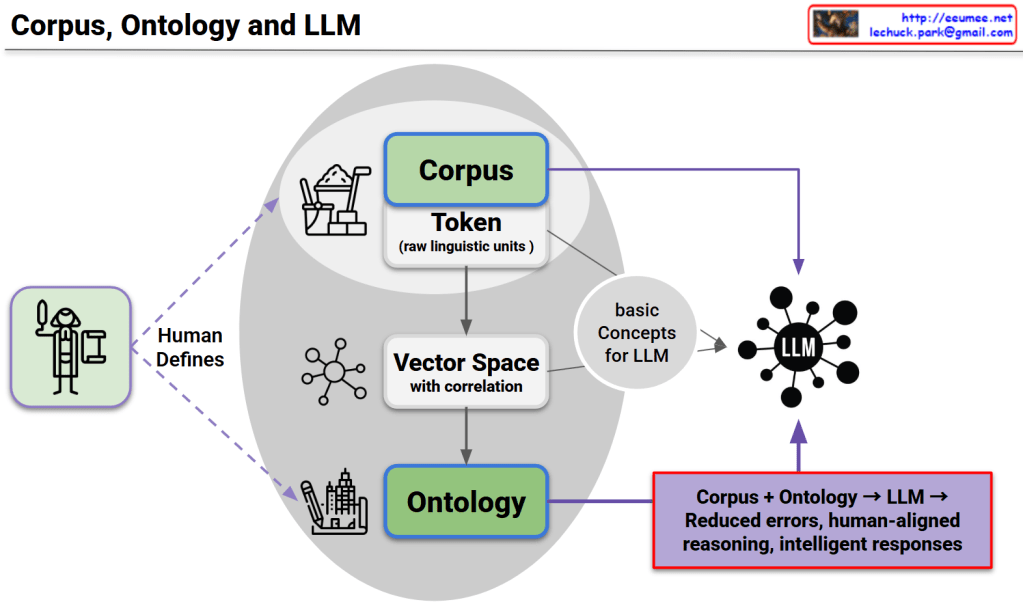
This diagram presents a unified framework consisting of three core structures, their interconnected relationships, and complementary utilization as the foundation for LLM advancement.
1. Corpus Structure
2. Ontology Structure
3. LLM Structure
Each structure compensates for the limitations of others:
This triangular complementary structure overcomes the limitations of single approaches to achieve:
This represents the core foundation for next-generation LLM development.
With Claude



Operational Performance Levels (Color-coded meanings):
Objective: keep <Green> higher than <Blue>
Objective: move <Green> to <Red>
1. Importance of Sequential Approach
2. Cost Efficiency Paradox
3. Dynamic Equilibrium Maintenance
This model visualizes the core principle of modern system operations: “Stability is the prerequisite for efficiency.” Rather than pursuing performance improvements alone, it presents strategic guidelines for achieving genuine operational efficiency through gradual and sustainable optimization built upon a solid foundation of stability.
The framework emphasizes that true operational excellence comes not from aggressive optimization, but from maintaining the optimal balance between risk mitigation and performance enhancement, ensuring long-term business value creation through sustainable operational practices.
With Claude

This diagram illustrates the Memory Bound phenomenon in computer systems.
Memory bound refers to a situation where the overall processing speed of a computer is limited not by the computational power of the CPU, but by the rate at which data can be read from memory.
The Processing Elements (PEs) on the right have high computational capabilities, but the overall system performance is constrained by the slower speed of data retrieval from memory.
Memory bound occurs when system performance is limited by memory access speed rather than computational power. This bottleneck commonly arises from large data transfers, cache misses, and memory bandwidth constraints. It represents a critical challenge in modern computing, particularly affecting GPU computing and AI/ML workloads where processing units often wait for data rather than performing calculations.
With Claude

