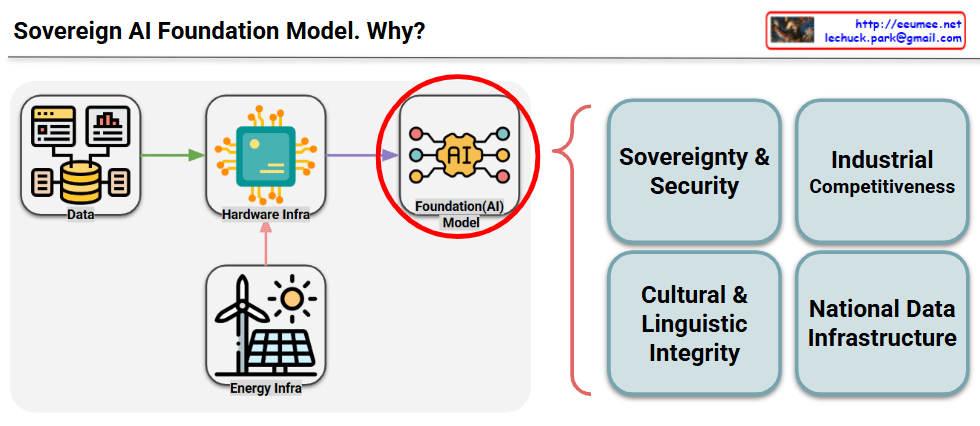
This diagram illustrates the concept of “Sovereign AI Foundation Model” and explains why it’s necessary.
Structure Analysis
Left Side (Infrastructure Elements):
- Data
- Hardware Infrastructure (Hardware Infra)
- Energy Infrastructure (Energy Infra)
These three elements are connected to the central Foundation AI Model.
Why Sovereign AI is Needed (Four boxes on the right)
- Sovereignty & Security
- Securing national AI technology independence
- Data security and technological autonomy
- Digital Sovereignty, National Security, Avoid Tech-Colonization, Data Jurisdiction, On-Premise Control.
- Industrial Competitiveness
- Strengthening AI-based competitiveness of national industries
- Gaining advantages in technological hegemony competition
- Ecosystem Enabler, Beyond ‘Black Box’, Deep Customization, Innovation Platform, Future Industries.
- Cultural & Linguistic Integrity
- Developing AI models specialized for national language and culture
- Preserving cultural values and linguistic characteristics
- Cultural Context, Linguistic Nuance, Mitigate Bias, Preserve Identity, Social Cohesion.
- National Data Infrastructure
- Systematic data management at the national level
- Securing data sovereignty
- Data Standardization, Break Data Silos, High-Quality Structured Data, AI-Ready Infrastructure, Efficiency & Scalability.
Key Message
This diagram systematically presents why each nation should build independent AI foundation models based on their own data, hardware, and energy infrastructure, rather than relying on foreign companies’ AI models. It emphasizes the necessity from the perspectives of technological sovereignty, competitiveness, cultural identity, and data independence.
The diagram essentially argues that nations need to develop their own AI capabilities to maintain control over their digital future and protect their national interests in an increasingly AI-driven world.
WIth Claude


