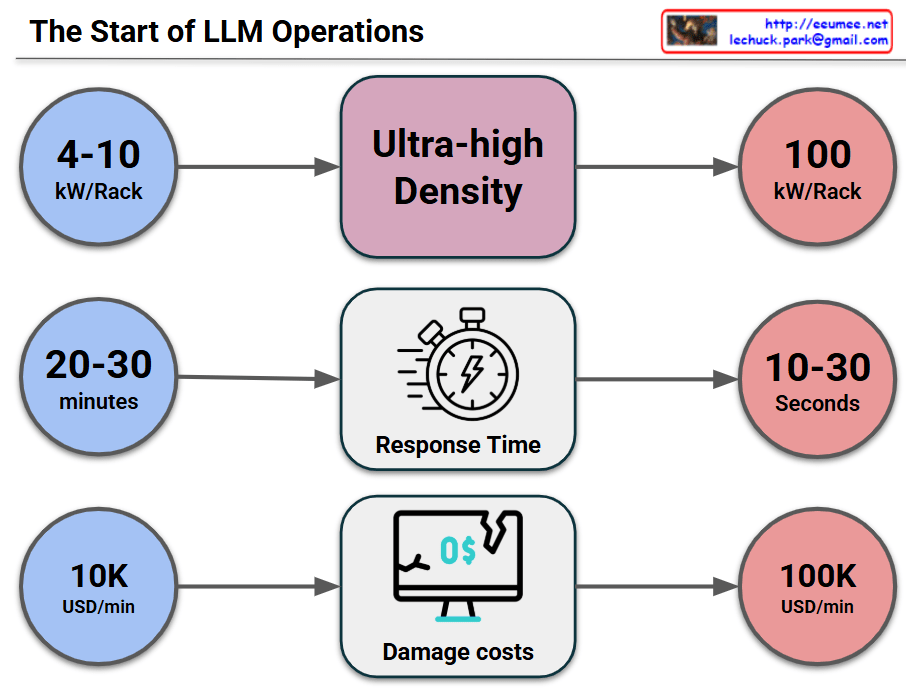
This image visually compares the critical changes and risks that occur when a data center or IT infrastructure transitions to an “Ultra-high Density” environment across three key metrics.
1. Surge in Power Density (Top Row)
- Past/Standard Environment (Blue): Racks typically operated at a power density of 4-10 kW per Rack.
- Transition (Middle): The shift toward Ultra-high Density infrastructure (driven by AI, High-Performance Computing, etc.).
- Current/Ultra-high Density (Red): Power density explodes to 100 kW per Rack, which is a 10-fold increase.
2. Drastic Drop in Response Time (Middle Row)
- Past/Standard Environment: In the event of a cooling failure or system issue, operators had a comfortable golden window of 20-30 minutes to react before systems went down.
- Transition: Focusing on the change in Response Time.
- Current/Ultra-high Density: Due to the massive, instantaneous heat generation, the reaction window plummets to a mere 10-30 seconds. This makes manual human intervention practically impossible.
3. Explosion of Damage Costs (Bottom Row)
- Past/Standard Environment: The financial loss caused by system downtime was around $10,000 (10K USD) per minute.
- Transition: Focusing on the change in Damage costs.
- Current/Ultra-high Density: Because of the high value of the equipment and the critical nature of the data being processed, the cost of downtime skyrockets to $100,000 (100K USD) per minute—a 10x increase.
💡 Overall Summary
The core message of this infographic is a strong warning: “In ultra-high density environments reaching 100kW per rack, the window for disaster response shrinks from minutes to mere seconds, while the financial loss per minute multiplies tenfold.” This perfectly illustrates why immediate, automated cooling and response systems (such as liquid cooling or AI-driven automation) are no longer optional, but mandatory for modern data centers.
#DataCenter#UltraHighDensity#HighDensityComputing#ITInfrastructure#Downtime#CostOfDowntime#RiskManagement
With Gemini