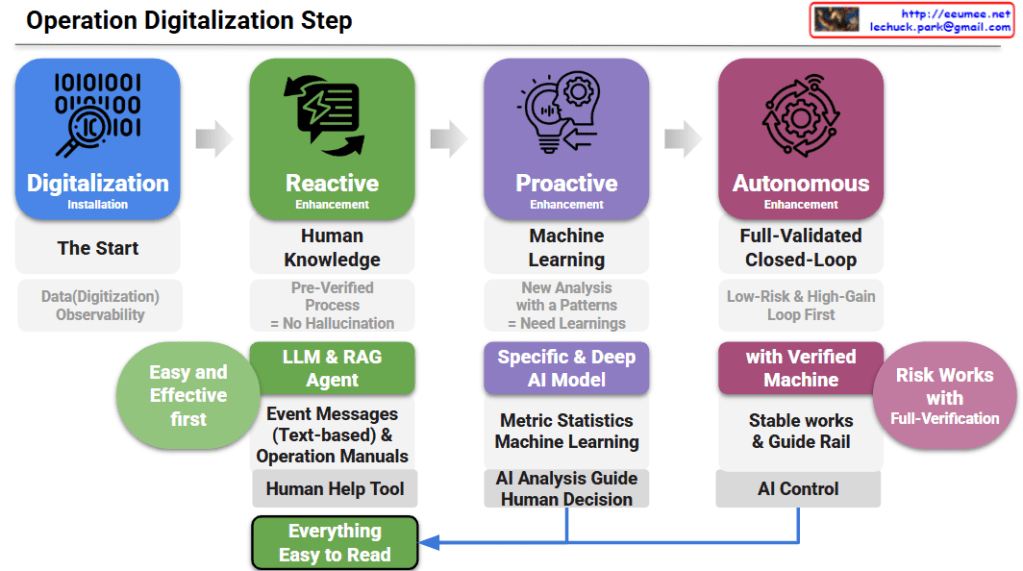
Operation Digitalization Step: A 4-Step Roadmap
Step 1: Digitalization (The Start)
- Goal: Securing data digitization and observability. It is the foundational phase of gathering and monitoring data before applying any advanced automation.
Step 2: Reactive Enhancement (Human Knowledge)
- Goal: Applying LLM & RAG agents as a “Human Help Tool.”
- Details: It relies on pre-verified processes to prevent AI hallucinations. By analyzing text-based event messages and operation manuals, it provides an “Easy and Effective first” approach to assist human operators.
Step 3: Proactive Enhancement (Machine Learning)
- Goal: Deriving new insights through pattern analysis and machine learning.
- Details: It utilizes specific and deep AI models based on metric statistics to provide an “AI Analysis Guide.” However, the final action still relies on a “Human Decision.”
Step 4: Autonomous Enhancement (Full-Validated Closed-Loop)
- Goal: Achieving stable, AI-controlled operations.
- Details: It prioritizes low-risk, high-gain loops. Through verified machines and strict guide rails, the system executes autonomous “AI Control” under full verification to manage risks.
- Core Feedback Loop: The outcomes from both human decisions (Step 3) and AI control (Step 4) are ultimately designed to make “Everything Easy to Read,” ensuring transparency and intuitive understanding for operators.
- Progressive Evolution: The roadmap illustrates a strategic 4-step journey from basic data observability to fully autonomous, AI-controlled operations.
- Practical AI Adoption: It emphasizes a safe, low-risk strategy, starting with LLM/RAG as human-assist tools before advancing to predictive machine learning and closed-loop automation.
- Human-Centric Transparency: Regardless of the automation level, the ultimate design ensures all AI actions and system insights remain intuitive and “Easy to Read” for human operators.
#OperationDigitalization #AIOps #AutonomousOperations #DataCenterManagement #ITInfrastructure #LLM #RAG #MachineLearning #DigitalTransformation