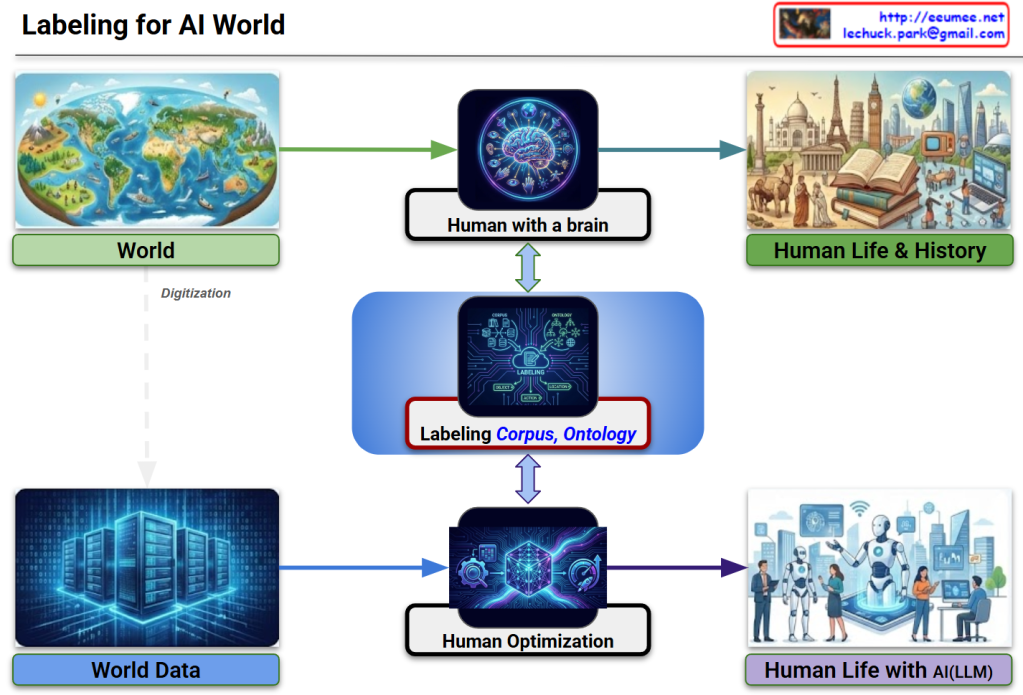
The image illustrates a logical framework titled “Labeling for AI World,” which maps how human cognitive processes are digitized and utilized to train Large Language Models (LLMs). It emphasizes the transition from natural human perception to optimized AI integration.
1. The Natural Cognition Path (Top)
This track represents the traditional human experience:
World to Human with a Brain: Humans sense the physical world through biological organs, which the brain then analyzes and processes into information.
Human Life & History: This cognitive processing results in the collective knowledge, culture, and documented history of humanity.
2. The Digital Optimization Path (Bottom)
This track represents the technical pipeline for AI development:
World Data: Through Digitization, the physical world is converted into raw data stored in environments like AI Data Centers.
Human Optimization: This raw data is refined through processes like RLHF (Reinforcement Learning from Human Feedback) or fine-tuning to align AI behavior with human intent.
Human Life with AI (LLM): The end goal is a lifestyle where humans and LLMs coexist, with the AI acting as a sophisticated partner in daily life.
3. The Central Bridge: Labeling (Corpus & Ontology)
The most critical element of the diagram is the central blue box, which acts as a bridge between human logic and machine processing:
Corpus: Large-scale structured text data necessary for training.
Ontology: The formal representation of categories, properties, and relationships between concepts that define the human “worldview.”
The Link: High-quality Labeling ensures that AI optimization is grounded in human-defined logic (Ontology) and comprehensive language data (Corpus), ensuring both Quality and Optimization.
Summary
The diagram demonstrates that Data Labeling, guided by Corpus and Ontology, is the essential mechanism that translates human cognition into the digital realm. It ensures that LLMs are not just processing raw numbers, but are optimized to understand the world through a human-centric logical framework.
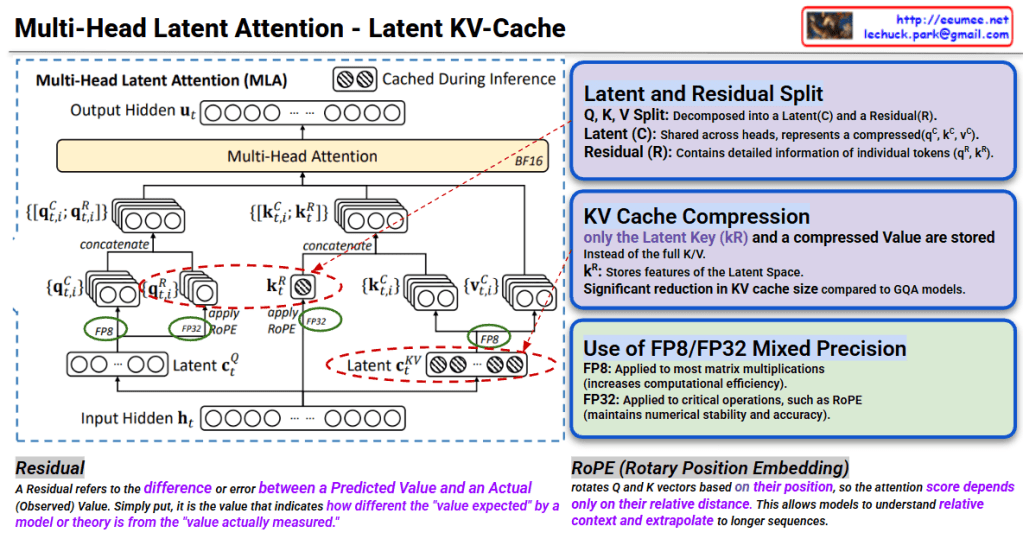
This image explains the Multi-Head Latent Attention (MLA) mechanism and Latent KV-Cache technique for efficient inference in transformer models.
Core Concepts
1. Latent and Residual Split
Q, K, V are decomposed into two components:
Latent (C): Compressed representation shared across heads (q^c, k^c, v^c)
Residual (R): Contains detailed information of individual tokens (q^R, k^R)
2. KV Cache Compression
Instead of traditional approach, stores only in compressed form:
k^R (Latent Key): Stores only Latent Space features
Achieves significant reduction in KV cache size compared to GQA models
3. Operation Flow
Generate Latent c_t^Q from Input Hidden h_t (using FP8)
Create q_{t,i}^C, q_{t,i}^R through Latent
k^R and v^c are concatenated and fed to Multi-Head Attention
Caching during inference: Only k^R and compressed Value stored (shown with checkered icon)
Apply RoPE (Rotary Position Embedding) for position information
4. FP8/FP32 Mixed Precision
FP8: Applied to most matrix multiplications (increases computational efficiency)
FP32: Applied to critical operations like RoPE (maintains numerical stability)
Key Advantages
Memory Efficiency: Caches only compressed representations instead of full K, V
Computational Efficiency: Fast inference using FP8
Long Sequence Processing: Enables understanding of long contexts through relative position information
Residual & RoPE Explanation
Residual: The difference between predicted and actual values (“difference between expected and measured values”)
RoPE: A technique that rotates Q and K vectors based on position, allowing attention scores to be calculated using only relative distances
Summary
This technique represents a cutting-edge optimization for LLM inference that dramatically reduces memory footprint by storing only compressed latent representations in the KV cache while maintaining model quality. The combination of latent-residual decomposition and mixed precision (FP8/FP32) enables both faster computation and longer context handling. RoPE further enhances the model’s ability to understand relative positions in extended sequences.
For accuracy-critical or sensitive math operations
Summary
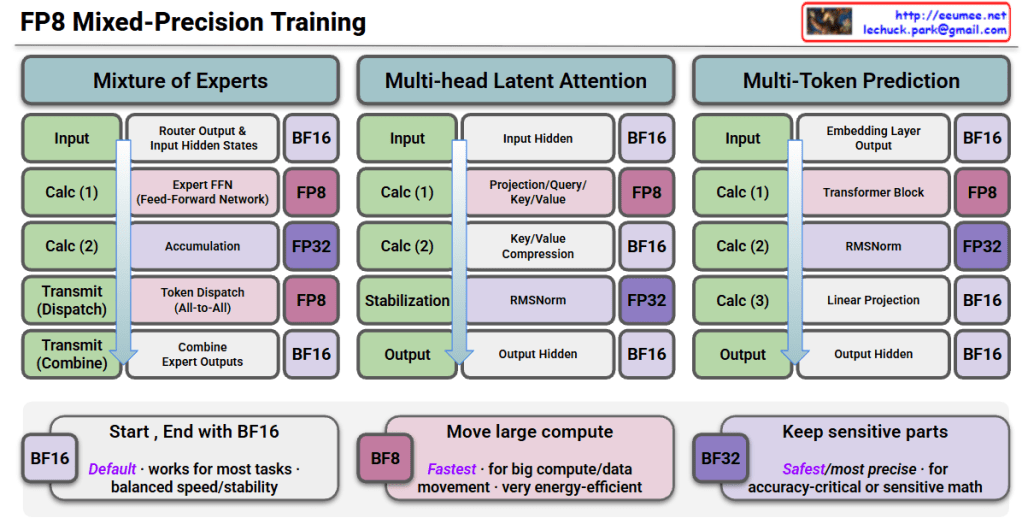
FP8 mixed-precision training strategically uses different numerical precisions across model operations: FP8 for compute-intensive operations (FFN, attention, transformers) to maximize speed and efficiency, FP32 for sensitive operations like accumulation and normalization to maintain numerical stability, and BF16 for input/output and communication to balance performance. This approach enables faster training with lower energy consumption while preserving model accuracy, making it ideal for training large-scale AI models efficiently.
PUE Improvement: Power Usage Effectiveness (overall power efficiency metric)
Key Message
This diagram emphasizes that for successful AI implementation:
Technical Foundation: Both Data/Chips (Computing) and Power/Cooling (Infrastructure) are necessary
Tight Integration: These two axes are not separate but must be firmly connected like a chain and optimized simultaneously
Implementation Technologies: Specific advanced technologies for stability and optimization in each domain must provide support
The central link particularly visualizes the interdependent relationship where “increasing computing power requires strengthening energy and cooling in tandem, and computing performance cannot be realized without infrastructure support.”
Summary
AI systems require two inseparable pillars: Computing (Data/Chips) and Infrastructure (Power/Cooling), which must be tightly integrated and optimized together like links in a chain. Each pillar is supported by advanced technologies spanning from AI model optimization (FlashAttention, Quantization) to next-gen hardware (GB200, TPU) and sustainable infrastructure (SMR, Liquid Cooling, AI-driven optimization). The key insight is that scaling AI performance demands simultaneous advancement across all layers—more computing power is meaningless without proportional energy supply and cooling capacity.
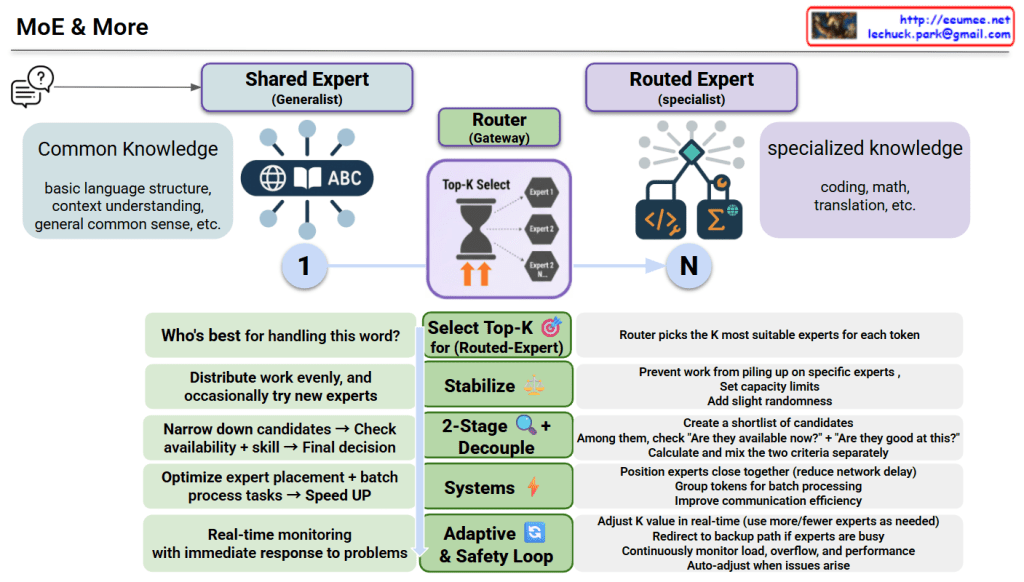
This diagram illustrates an advanced Mixture of Experts (MoE) model architecture.
Core Structure
1. Two Types of Experts
Shared Expert (Generalist)
Handles common knowledge: basic language structure, context understanding, general common sense
Applied universally to all tokens
Routed Expert (Specialist)
Handles specialized knowledge: coding, math, translation, etc.
Router selects the K most suitable experts for each token
2. Router (Gateway) Role
For each token, determines “Who’s best for handling this word?” by:
Selecting K experts out of N available specialists
Using Top-K selection mechanism
Key Optimization Techniques
Select Top-K 🎯
Chooses K most suitable routed experts
Distributes work evenly and occasionally tries new experts
Stabilize ⚖️
Prevents work from piling up on specific experts
Sets capacity limits and adds slight randomness
2-Stage Decouple 🔍
Creates a shortlist of candidate experts
Separately checks “Are they available now?” + “Are they good at this?”
Calculates and mixes the two criteria separately before final decision
Validates availability and skill before selection
Systems ⚡
Positions experts close together (reduces network delay)
Groups tokens for batch processing
Improves communication efficiency
Adaptive & Safety Loop 🔄
Adjusts K value in real-time (uses more/fewer experts as needed)
Redirects to backup path if experts are busy
Continuously monitors load, overflow, and performance
Auto-adjusts when issues arise
Purpose
This system enhances both efficiency and performance through:
Optimized expert placement
Accelerated batch processing
Real-time monitoring with immediate problem response
Summary
MoE & More combines generalist experts (common knowledge) with specialist experts (domain-specific skills), using an intelligent router to dynamically select the best K experts for each token. Advanced techniques like 2-stage decoupling, stabilization, and adaptive safety loops ensure optimal load balancing, prevent bottlenecks, and enable real-time adjustments for maximum efficiency. The result is a faster, more efficient, and more reliable AI system that scales intelligently.
This diagram illustrates the AI Stabilization & Optimization framework addressing the reality where AI’s explosive development encounters critical physical and technological barriers.
Power: UPS, dual path, renewable mix for power stability
Cooling: CRAC control, monitoring for thermal stability
Optimization – Breaking Through/Approaching Walls
Breaking limits or maximizing utilization:
LM SW: MoE, lightweight solutions for efficiency maximization
Computing: Near-memory, neuromorphic, quantum for breakthrough
Power: AI forecasting, demand response for power optimization
Cooling: Immersion cooling, heat reuse for thermal innovation
Summary
This framework demonstrates that AI’s explosive innovation requires a dual strategy: stabilization to manage rapid changes and optimization to overcome physical limits, both happening simultaneously in response to real-world constraints.