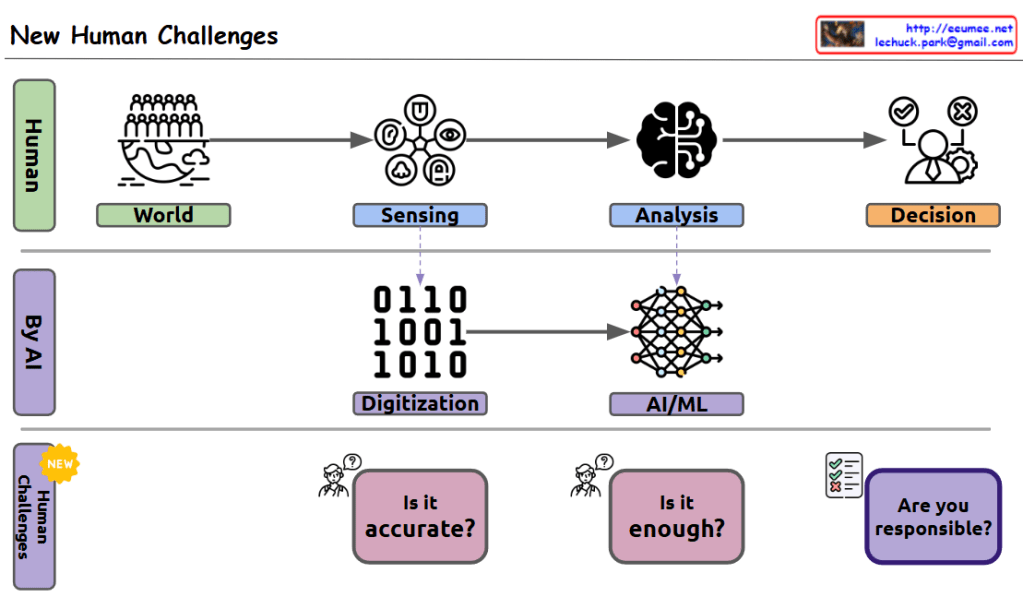
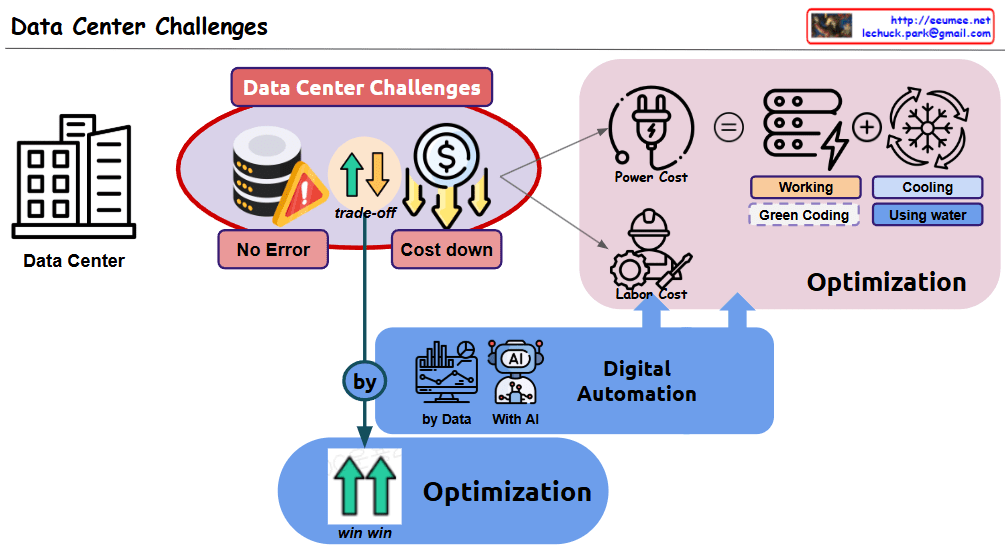
This image illustrates a diagram of power requirements and management for AI data centers:
Top Section – “More Power & Control”:
- Diverse power sources: SMR (Small Modular Reactor), Reusable Energy (wind, solar), and ESS (Energy Storage System)
- Power control system directing electricity from these various sources to the data center through “Power Control with Grid”
- Integrated system for reliable and sustainable power supply
Bottom Section – “Optimization”:
- Power distribution system through transformers and power supply units
- Central control system for power routing
- Load Balancing and Dynamic Power Management capabilities
- Efficient power distribution to server racks based on GPU workload
- “More Stable” indication emphasizing system reliability
This diagram highlights the importance of diversifying reliable power sources, efficient power control, and optimized power management according to GPU workload in AI data centers.
With Claude