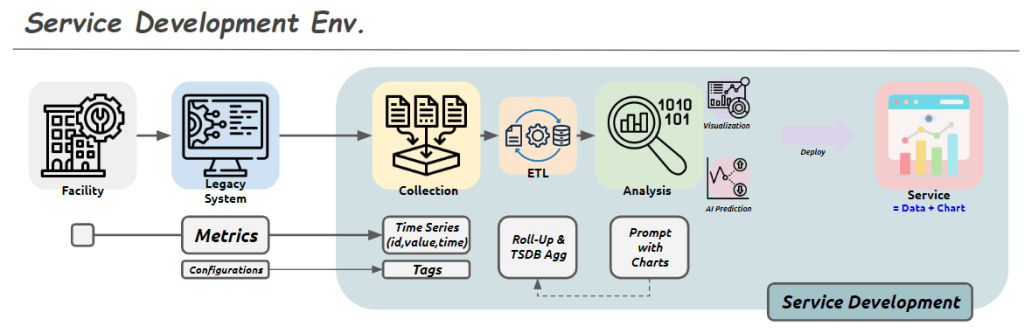
From Claude with some prompting
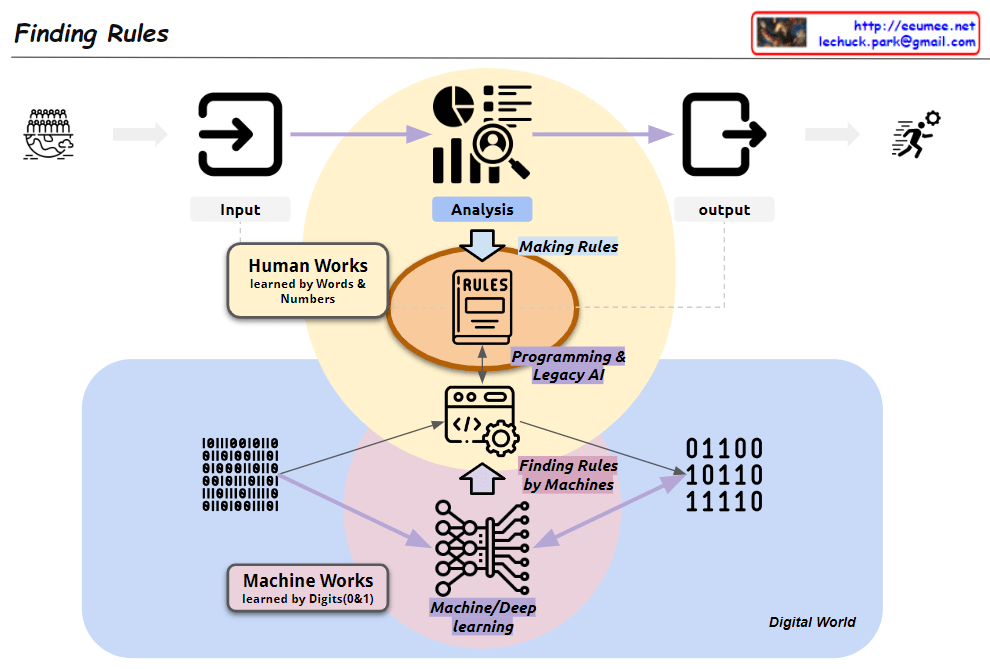
This image, titled “Finding Rules,” illustrates the contrast between two major learning paradigms:
- Traditional Human-Centric Learning Approach:
- Represented by the upper yellow circle
- “Human Works”: Learning through human language and numbers
- Humans directly analyze data and create rules
- Leads to programming and legacy AI systems
- Machine Learning (ML) Approach:
- Represented by the lower pink circle
- “Machine Works”: Learning through binary digits (0 and 1)
- Based on big data
- Uses machine/deep learning to automatically discover rules
- “Finding Rules by Machines”: Machines directly uncover patterns and rules
The diagram showcases a paradigm shift:
- Two coexisting methods in the process from input to output
- Transition from human-generated rules to machine-discovered rules
- Emphasis on data processing in the “Digital World”
Key components:
- Input and Output: Marking the start and end of the process
- Analysis: Central to both approaches
- Rules: Now discoverable by both humans and machines
- Programming & Legacy AI: Connected to the human-centric approach
- Machine/Deep Learning: Core of the ML approach
This visualization effectively demonstrates the evolution in data analysis and rule discovery brought about by advancements in artificial intelligence and machine learning. It highlights the shift from converting data into human-readable formats for analysis to leveraging vast amounts of binary data for machine-driven rule discovery.