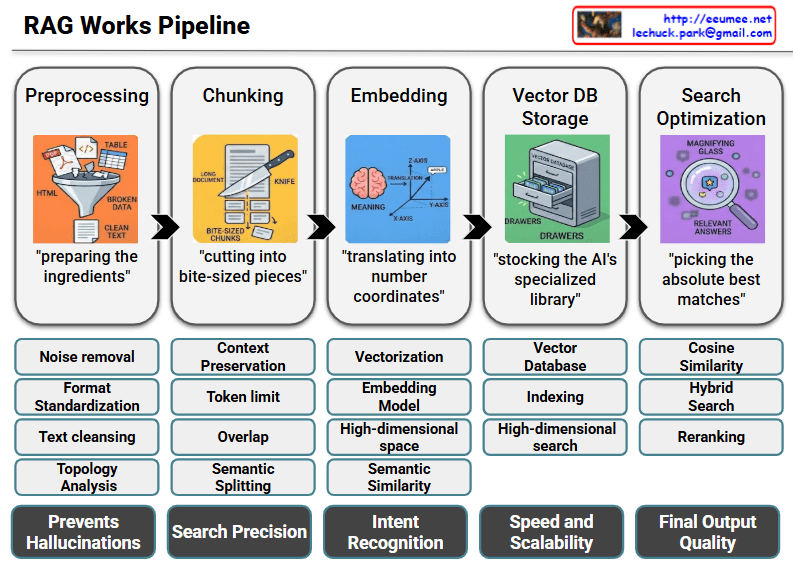
This image illustrates the RAG (Retrieval-Augmented Generation) Works Pipeline, breaking down the complex data processing workflow into five intuitive steps using relatable analogies like cooking and organizing.
Here is a step-by-step breakdown of the pipeline:
- Step 1: Preprocessing (“preparing the ingredients”)
Just like prepping ingredients for a meal, this step filters raw, unstructured data from various formats (PDFs, HTML, tables) through a funnel to extract clean text. By handling noise removal, format standardization, and text cleansing, it establishes a solid data foundation that ultimately prevents AI hallucinations. - Step 2: Chunking (“cutting into bite-sized pieces”)
Long documents are sliced into smaller, manageable pieces that the AI model can easily process. Techniques like semantic splitting and overlapping ensure that the original context is preserved without exceeding the AI’s token limits. This careful division drastically improves the system’s overall search precision. - Step 3: Embedding (“translating into number coordinates”)
Here, the text chunks are converted into mathematical vectors mapped in a high-dimensional space (X, Y, Z axes). This vectorization captures the underlying semantic meaning and context of the text, allowing the system to go beyond simple keyword matching and achieve true intent recognition. - Step 4: Vector DB Storage (“stocking the AI’s specialized library”)
The embedded vectors are systematically stored and indexed in a Vector Database. Think of it as a highly organized, specialized filing cabinet designed specifically for AI. Efficient indexing allows for high-dimensional searches, ensuring optimal speed and scalability even as the dataset grows massively. - Step 5: Search Optimization (“picking the absolute best matches”)
Acting as a magnifying glass, this final step identifies and retrieves the most relevant information to answer a user’s query. Using advanced methods like cosine similarity, hybrid search, and reranking, the system pinpoints the exact data needed. This precise retrieval guarantees the highest final output quality for the AI’s generated response.
#RAG #RetrievalAugmentedGeneration #GenerativeAI #LLM #VectorDatabase #DataPipeline #MachineLearning #AIArchitecture #TechExplanation #ArtificialIntelligence
With Gemini
