Parallelism (2) – Pipeline vs Tensor Parallelism
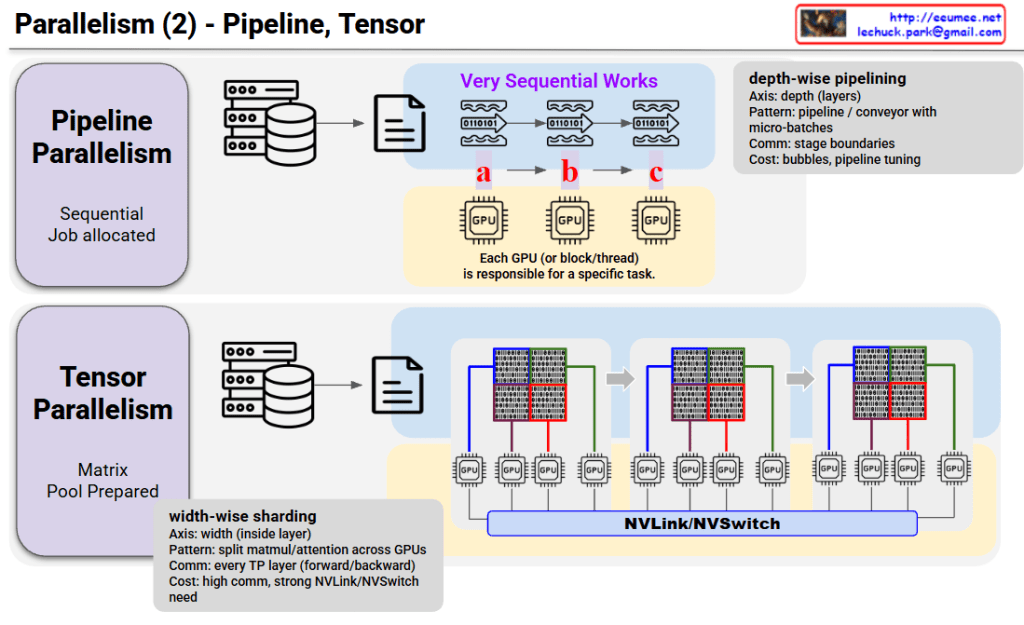
This image compares two parallel processing techniques: Pipeline Parallelism and Tensor Parallelism.
Pipeline Parallelism
Core Concept:
- Sequential work is divided into multiple stages
- Each GPU is responsible for a specific task (a → b → c)
Characteristics:
- Axis: Depth-wise – splits by layers
- Pattern: Pipeline/conveyor belt with micro-batches
- Communication: Only at stage boundaries
- Cost: Bubbles (idle time), requires pipeline tuning
How it works: Data flows sequentially like waves, with each GPU processing its assigned stage before passing to the next GPU.
Tensor Parallelism
Core Concept:
- Matrix pool is prepared and split in advance
- All GPUs simultaneously process different parts of the same data
Characteristics:
- Axis: Width-wise – splits inside layers
- Pattern: Width-wise sharding – splits matrix/attention across GPUs
- Communication: Occurs at every Transformer layer (forward/backward)
- Cost: High communication overhead, requires strong NVLink/NVSwitch
How it works: Large matrices are divided into chunks, with each GPU processing simultaneously while continuously communicating via NVLink/NVSwitch.
Key Differences
| Aspect | Pipeline | Tensor |
|---|---|---|
| Split Method | Layer-wise (vertical) | Within-layer (horizontal) |
| GPU Role | Different tasks | Parts of same task |
| Communication | Low (stage boundaries) | High (every layer) |
| Hardware Needs | Standard | High-speed interconnect required |
Summary
Pipeline Parallelism splits models vertically by layers with sequential processing and low communication cost, while Tensor Parallelism splits horizontally within layers for parallel processing but requires high-speed interconnects. These two techniques are often combined in training large-scale AI models to maximize efficiency.
#ParallelComputing #DistributedTraining #DeepLearning #GPUOptimization #MachineLearning #ModelParallelism #AIInfrastructure #NeuralNetworks #ScalableAI #HPC
With Claude