With Claude
Comprehensive Analysis of Server Room HVAC System Configuration and Operation
- Physical Configuration
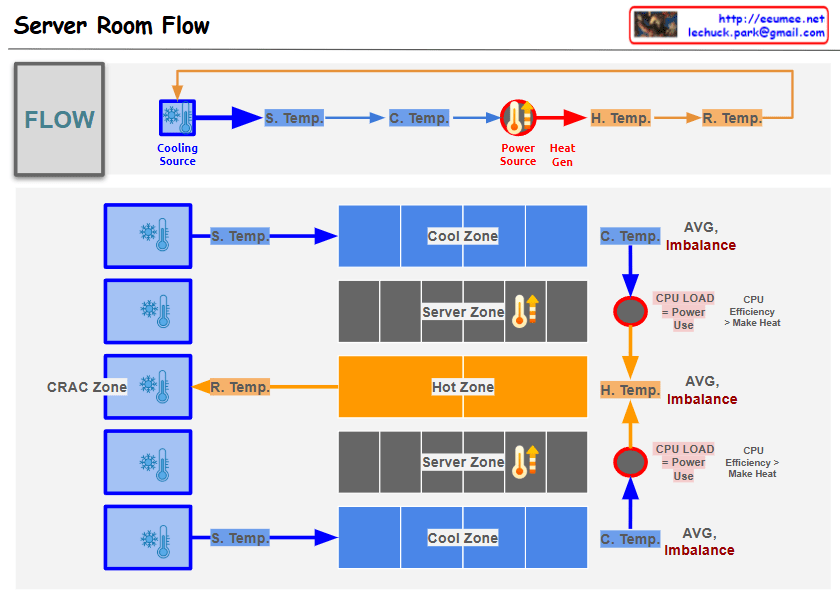
- Multiple cooling units arranged in CRAC (Computer Room Air Conditioning) Zone
- Three-tier structure: Cool Zone, Server Zone, Hot Zone
- Upper and lower distribution structure for air circulation
- Temperature Monitoring System
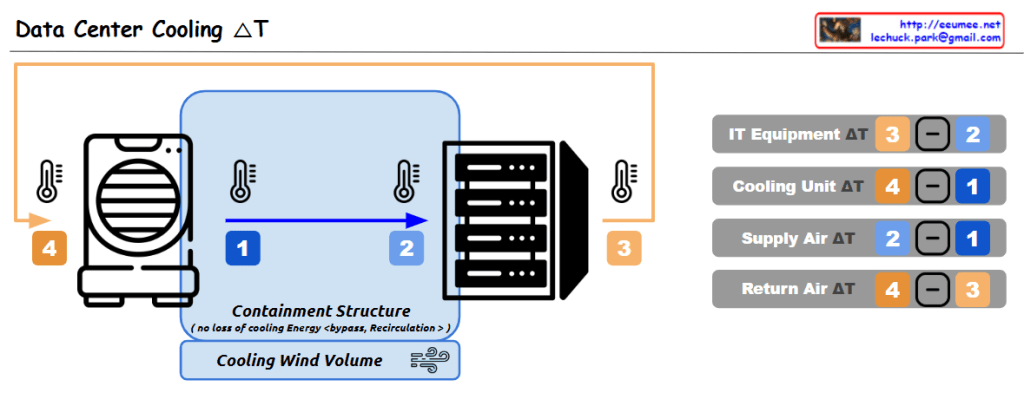
- Supply Temperature (S. Temp): Cooling unit output temperature
- Cooling Zone Temperature (C. Temp): Pre-server intake temperature
- Hot Zone Temperature (H. Temp): Server exhaust temperature
- Return Temperature (R. Temp): CRAC intake temperature
- Efficiency Management Indicators
- AVG. Imbalance monitoring for each section
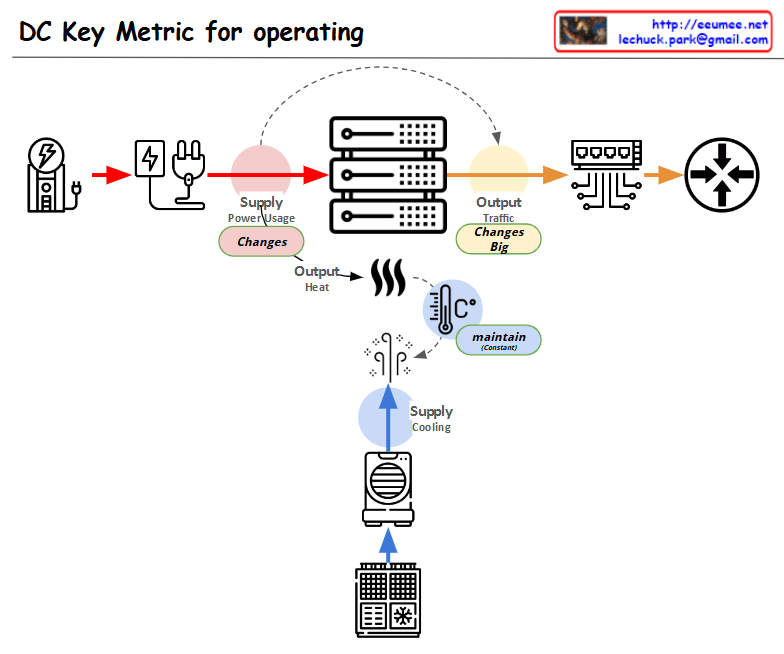
- CPU load and power consumption correlation analysis
- CPU efficiency and heat generation relationship tracking
- Analysis Points
- Delta T analysis between sections
- Temperature variation patterns by time/season
- Power efficiency and cooling efficiency correlation
- System stability prediction indicators
- Operational Goals
- Operating cost optimization
- Provide stable server operating environment
- Energy-efficient cooling system operation
- Proactive problem detection and response