With a Claude
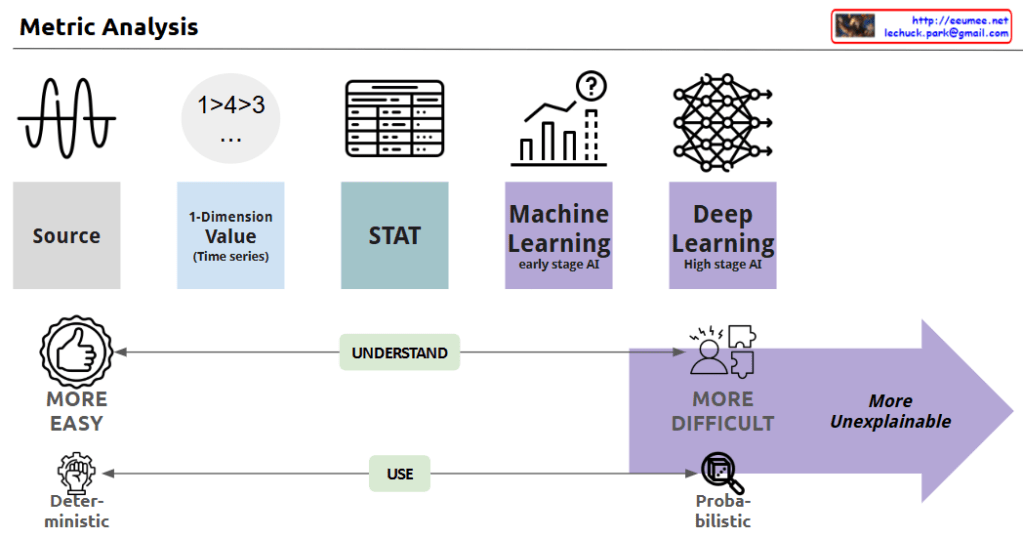
This image depicts the evolution of data analysis techniques, from simple time series analysis to increasingly sophisticated statistical methods, machine learning, and deep learning.
As the analysis approaches become more advanced, the process becomes less transparent and the results more difficult to explain. Simple techniques are more easily understood and allow for deterministic decision-making. But as the analysis moves towards statistics, machine learning, and AI, the computations become more opaque, leading to probabilistic rather than definitive conclusions. This trade-off between complexity and explainability is the key theme illustrated.
In summary, the progression shows how data analysis methods grow more powerful yet less interpretable, requiring a balance between the depth of insights and the ability to understand and reliably apply the results.






