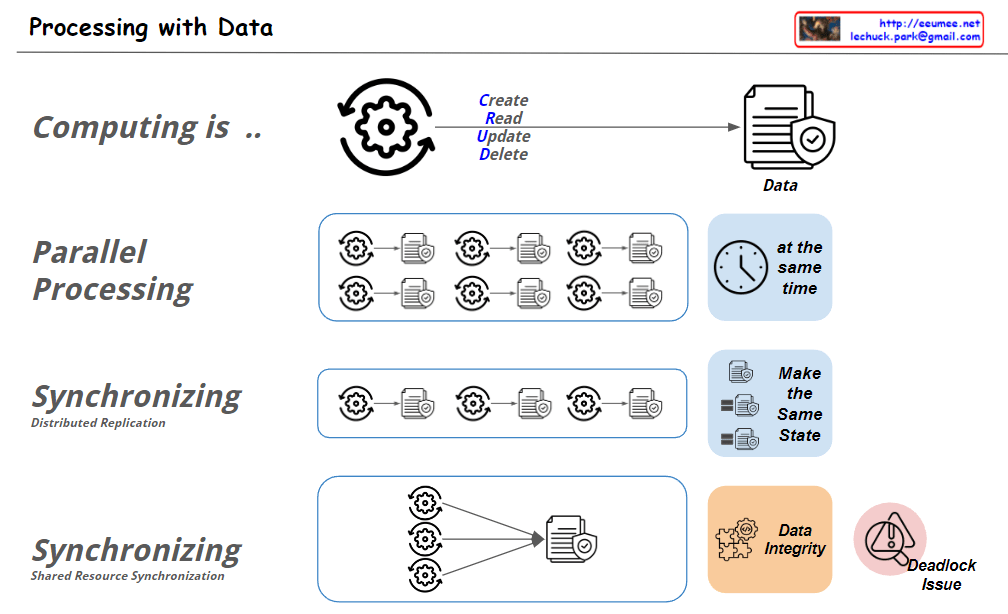
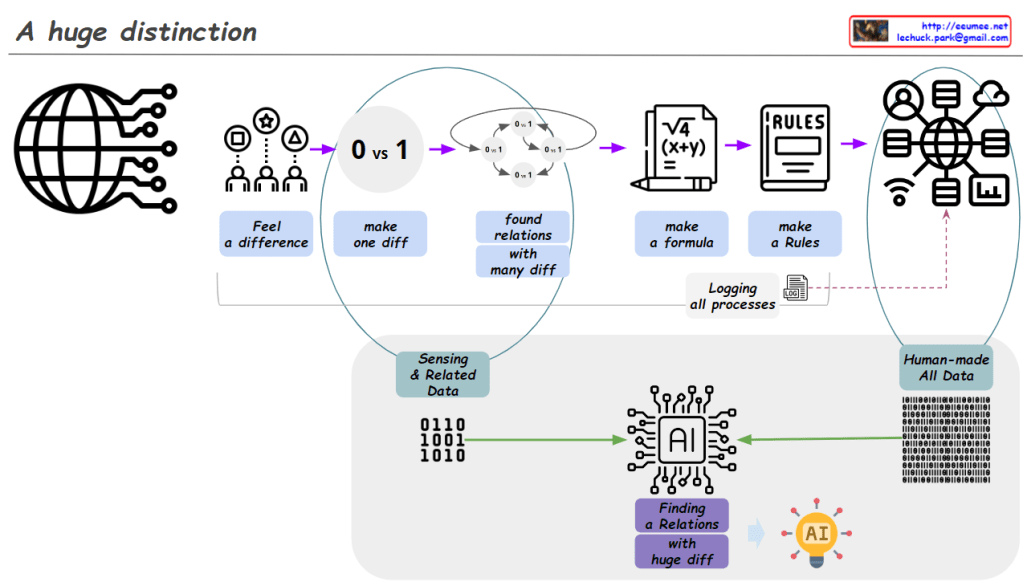
From Claude with some prompting Image Analysis: “A huge distinction”
Human Data Processing:
“Feel a difference”: Humans start by recognizing basic differences.
“Make one diff (0 vs 1)”: Creating the most fundamental distinction.
“Found relations with many diff”: Discovering relationships among various differences.
“Make a formula”: Developing formulas based on discovered relationships.
“Make a Rules”: Establishing rules based on these formulas.
“Human-made All Data”: Accumulation of data created through this entire process.
Process Recording:
“Logging all processes”: The data creation process itself is recorded as data.
AI Data Processing:
“Sensing & Related Data”: AI receives basic sensory data and related information.
“Human-made All Data”: All human-created data serves as input for AI.
“Finding a Relations with huge diff”: AI analyzes relationships and differences within this vast dataset.
Result:
AI icon: Represents the final derivation of insights through AI.
Evaluation:
Insightfulness: The diagram effectively illustrates the fundamental difference between human data processing methods and AI’s data processing capabilities. It highlights how humans follow a step-by-step logical process, while AI can process large-scale data simultaneously.
Process Continuity: The diagram well expresses how human data processing forms the foundation for AI learning. This conveys the important concept that AI develops based on human knowledge and experience.
Importance of Data: By emphasizing the importance of digitalizing all processes, the diagram effectively represents the core of our modern data-centric society.
Visualization Effectiveness: Complex concepts are represented using simple icons and arrows, making them easy to understand.
Future Expectation: We look forward to seeing additional explanations about AI’s output results or its potential applications. This would enhance the comprehensiveness of the diagram, providing a fuller picture of the AI process from input to output and its real-world impact.
Overall, this image effectively contrasts human data processing with AI’s data analysis capabilities, showcasing how these two domains operate complementarily. It provides a clear visual representation of the journey from basic human distinctions to complex AI-driven insights, highlighting the ‘huge distinction’ in scale and capability between human and artificial intelligence processing.
From Claude with some prompting This diagram illustrates the cyclical evolution of computing infrastructure, emphasizing the re-entry into a new computing infrastructure era driven by AI technology:
Development cycle:
Traditional infrastructure era (Infra age) → Software era (SW Age) → New infrastructure era (New Infra age)
Core elements of the new infrastructure era:
AI/ML (highlighted with red circles): Processing humanity’s accumulated experiences and data
GPU: Key computing infrastructure for AI
Driving forces of development:
More Users
More Data
These are visualized by the icons at the bottom
Key connection points (highlighted with red circles):
PC: Increased user base due to personal computer proliferation
Internet: Enhanced global connectivity
Web: Improved information accessibility
Mobile: Anytime, anywhere access environment
AI/ML: Processing and utilization of accumulated data
Cyclical development:
User increase → Data increase → Infrastructure development to process this data → Attraction of more users, creating a cyclical structure
This diagram emphasizes that as AI technology begins to comprehensively process and utilize humanity’s accumulated experiences and data, it necessitates the expansion of new GPU-centric computing infrastructure to support this. It demonstrates a cyclical structure where processing more users and data leads to further infrastructure development, which in turn enables handling even more users and data.
From Claude with some prompting This image compares human intelligence and artificial intelligence, emphasizing that both are “equally unexplainable” in certain aspects:
Human Intelligence:
Uses 100% math and logic, but based on limited experience and data.
Labeled “Not 100% depend on Experience,” indicating experience alone is insufficient.
When decision-making under time constraints, humans make the “best choice” rather than a 100% perfect choice.
Shows a process of: Event → Decision with Time Limit → Action.
Artificial Intelligence:
Based on big data, GPU/CPU processing, and AI models (including LLMs).
Labeled as “Unexplainable AI Model,” highlighting the difficulty in fully interpreting AI decision-making processes.
Demonstrates a flow of: Data input → Neural network processing → “Nice but not 100%” output.
Like human intelligence, AI also makes best choices within limited data and time constraints.
Key Messages:
AI is not a simple logic calculator but a system mimicking human intelligence.
AI decisions, like human decisions, are not 100% perfect but the best choice under given conditions.
We should neither overestimate nor underestimate AI, but understand its limitations and possibilities in a balanced way.
Both human and artificial intelligence have unexplainable aspects, reflecting the complexity and limitations of both systems.
This image emphasizes the importance of accurately understanding and appropriately utilizing AI capabilities by comparing it with human intelligence. It reminds us that while AI is a powerful tool, human judgment and ethical considerations remain crucial. The comparison underscores that AI, like human intelligence, is making the best possible decisions based on available data and constraints, rather than providing infallible, 100% correct answers.
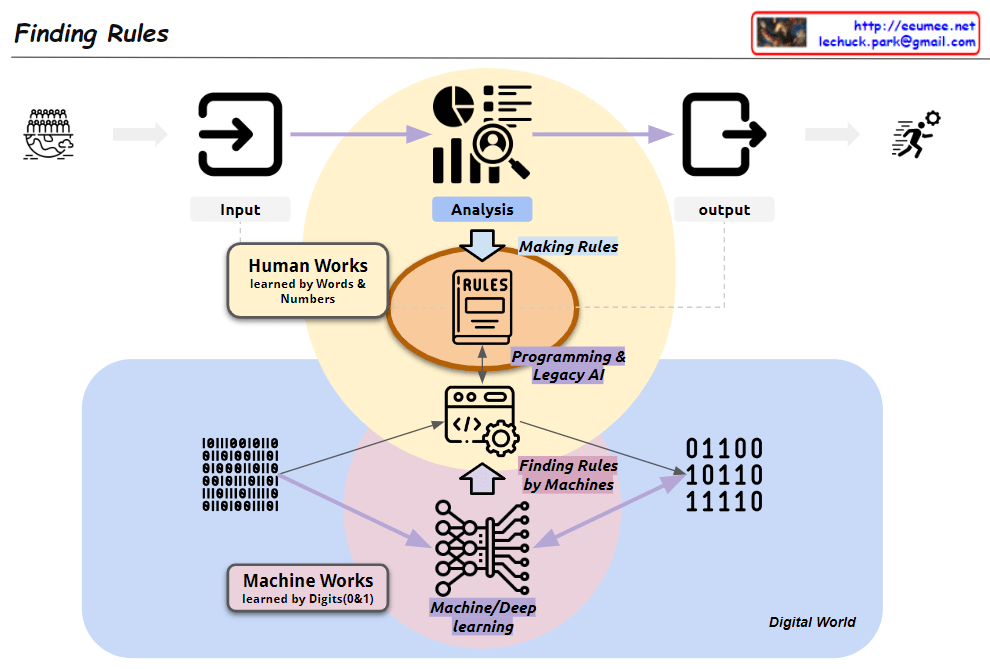
From Claude with some prompting This image, titled “Finding Rules,” illustrates the contrast between two major learning paradigms:
Traditional Human-Centric Learning Approach:
Represented by the upper yellow circle
“Human Works”: Learning through human language and numbers
Humans directly analyze data and create rules
Leads to programming and legacy AI systems
Machine Learning (ML) Approach:
Represented by the lower pink circle
“Machine Works”: Learning through binary digits (0 and 1)
Based on big data
Uses machine/deep learning to automatically discover rules
“Finding Rules by Machines”: Machines directly uncover patterns and rules
The diagram showcases a paradigm shift:
Two coexisting methods in the process from input to output
Transition from human-generated rules to machine-discovered rules
Emphasis on data processing in the “Digital World”
Key components:
Input and Output: Marking the start and end of the process
Analysis: Central to both approaches
Rules: Now discoverable by both humans and machines
Programming & Legacy AI: Connected to the human-centric approach
Machine/Deep Learning: Core of the ML approach
This visualization effectively demonstrates the evolution in data analysis and rule discovery brought about by advancements in artificial intelligence and machine learning. It highlights the shift from converting data into human-readable formats for analysis to leveraging vast amounts of binary data for machine-driven rule discovery.
From Claude with some prompting This image illustrates the data processing, analysis, and machine learning application process, emphasizing how errors can be amplified at each stage:
Data Flow:
Starts with RAW data.
Goes through multiple ETL (Extract, Transform, Load) processes, transforming into new forms of data (“NEW”) at each stage.
Time information is incorporated, developing into statistical data.
Finally, it’s processed through machine learning techniques, evolving into more sophisticated new data.
Error Propagation and Amplification:
Each ETL stage is marked with a “WHAT {IF.}” and a red X, indicating the possibility of errors.
Errors occurring in early stages propagate through subsequent stages, with their impact growing progressively larger, as shown by the red arrows.
The large red X at the end emphasizes how small initial errors can have a significant impact on the final result.
Key Implications:
As the data processing becomes more complex, the quality and accuracy of initial data become increasingly crucial.
Thorough validation and preparation for potential errors at each stage are necessary.
Particularly for data used in machine learning models, initial errors can be amplified, severely affecting model performance, thus requiring extra caution.
This image effectively conveys the importance of data quality management in data science and AI fields, and the need for systematic preparation against error propagation. It highlights that as data becomes more abstracted and processed, the potential impact of early errors grows, necessitating robust error mitigation strategies throughout the data pipeline.
Also presented in a circular structure, including:
“Data”: Shown as a graph icon
“Analysis(Visual)”: Represented by a monitor icon with charts
“Program”: Depicted by a code or document icon
This process is also marked with “xN”, indicating repeatability.
Right side: Integrated “Op. Process” and “D/T Service”
A larger circle contains the “Op. Process”, which in turn encompasses the “D/T Service”
Within the “D/T Service” circle, “Data Result” and “Operation” are connected by a bidirectional arrow.
This diagram appears to illustrate how operational processes and data/technology services interact and integrate, likely representing a data-driven operational and decision-making process.