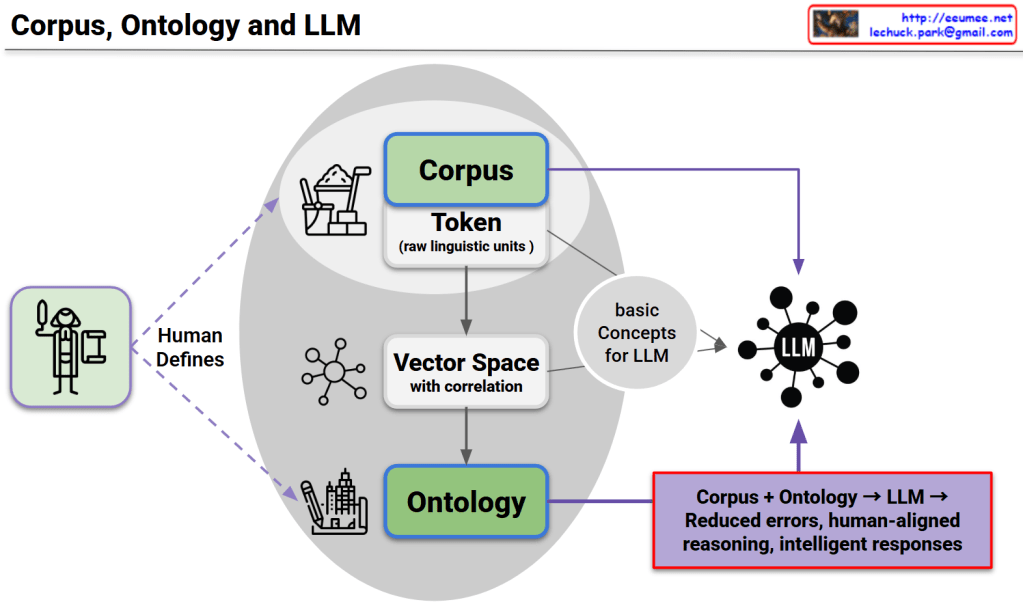
This diagram presents a unified framework consisting of three core structures, their interconnected relationships, and complementary utilization as the foundation for LLM advancement.
Three Core Structures
1. Corpus Structure
- Token-based raw linguistic data
- Provides statistical language patterns and usage frequency information
2. Ontology Structure
- Systematically human-defined conceptual knowledge structure
- Provides logical relationships and semantic hierarchies
3. LLM Structure
- Neural network-based language processing model
- Possesses pattern learning and generation capabilities
Interconnected Relationships and Interactions
- Corpus → Vector Space: Numerical representation transformation of linguistic data
- Ontology → Basic Concepts: Conceptual abstraction of structured knowledge
- Vector Space ↔ Ontology: Mutual validation between statistical patterns and logical structures
- Integrated Concepts → LLM: Multi-layered knowledge input
LLM Development Foundation through Complementary Relationships
Each structure compensates for the limitations of others:
- Corpus’s statistical accuracy + Ontology’s logical consistency → Balanced knowledge foundation
- Ontology’s explicit rules + LLM’s pattern learning → Flexible yet systematic reasoning
- Corpus’s real-usage data + LLM’s generative capability → Natural and accurate language generation
Final Achievement
This triangular complementary structure overcomes the limitations of single approaches to achieve:
- Error minimization
- Human-centered reasoning capabilities
- Intelligent and reliable response generation
This represents the core foundation for next-generation LLM development.
With Claude