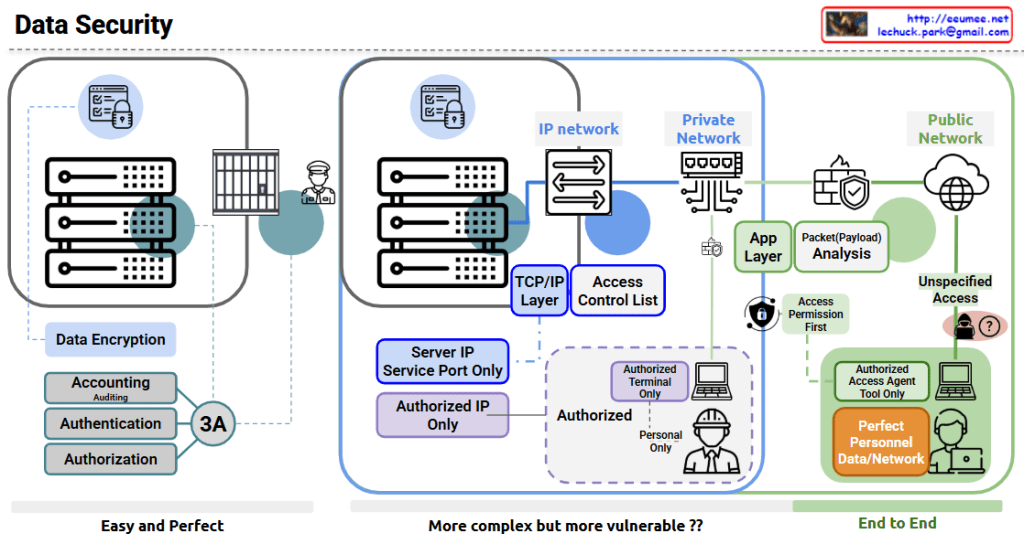
The image shows a comprehensive data security diagram with three main approaches to securing data systems. Let me explain each section:
- Left Section – “Easy and Perfect”:
- Features data encryption for secure storage
- Implements the “3A” security principles: Accounting (with Auditing), Authentication, and Authorization
- Shows server hardware protected by physical security (guard)
- Represents a straightforward but effective security approach
- Middle Section – “More complex but more vulnerable??”:
- Shows an IP network architecture with:
- Server IP and service port restrictions
- TCP/IP layer security
- Access Control Lists
- Authorized IP only policy
- Authorized terminal restrictions
- Personnel authorization controls
- Shows an IP network architecture with:
- Right Section – “End to End”:
- Divides security between Private Network and Public Network
- Includes:
- Application layer security
- Packet/Payload analysis
- Access Permission First principle
- Authorized Access Agent Tool restrictions
- “Perfect Personnel Data/Network” security approach
- Unspecified Access concerns (shown with question mark)
The diagram illustrates the evolution of data security approaches from simpler encryption and authentication methods to more complex network security architectures, and finally to comprehensive end-to-end security solutions. The diagram questions whether more complex systems might actually introduce more vulnerabilities, suggesting that complexity doesn’t always equal better security.
With Claude

