1. Prefill Phase (Input Analysis & Parallel Processing)
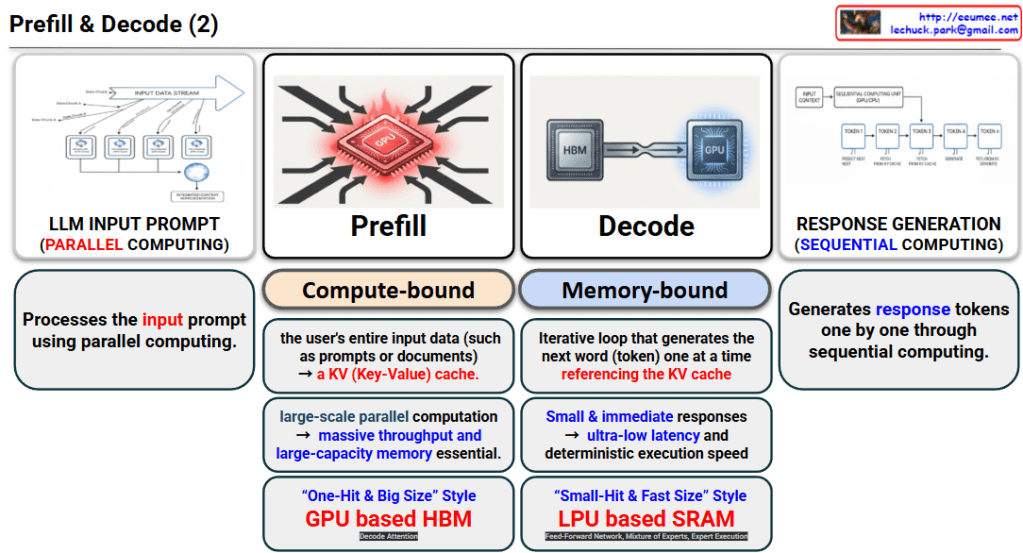
- Processing Method: It processes the user’s lengthy prompts or documents all at once using Parallel Computing.
- Bottleneck (Compute-bound): Since it needs to process a massive amount of data simultaneously, computational power is the most critical factor. This phase generates the KV (Key-Value) cache which is used in the next step.
- Requirements: Because it requires large-scale parallel computation, massive throughput and large-capacity memory are essential.
- Hardware Characteristics: The image describes this as a “One-Hit & Big Size” style, explaining that a GPU-based HBM (High Bandwidth Memory) architecture is highly suitable for handling such large datasets.
2. Decode Phase (Sequential Token Generation)
- Processing Method: Using the KV cache generated during the Prefill phase, this is a Sequential Computing process that generates the response tokens one by one.
- Bottleneck (Memory-bound): The computation itself is light, but the system must constantly access the memory (KV cache) to fetch and generate the next word. Therefore, memory access speed (bandwidth) becomes the limiting factor.
- Requirements: Because it needs to provide small and immediate responses to the user, ultra-low latency and deterministic execution speed are crucial.
- Hardware Characteristics: Described as a “Small-Hit & Fast Size” style, an LPU (Language Processing Unit)-based SRAM architecture is highly advantageous to minimize latency.
💡Summary
- Prefill is a compute-bound phase that processes user input in parallel all at once to create a KV cache, making GPU and HBM architectures highly suitable.
- Decode is a memory-bound phase that sequentially generates words one by one by referencing the KV cache, where LPU and SRAM architectures are advantageous for achieving ultra-low latency.
- Ultimately, an LLM operates by grasping the context through large-scale computation (Prefill) and then generating responses in real-time through fast memory access (Decode).
#LLM #Prefill #Decode #GPU_HBM #LPU_SRAM #AIArchitecture #ParallelComputing #UltraLowLatencyAI
With Gemini