📊A Tightly Coupled AI Architecture
1. The 5 Pillars & Potential Bottlenecks (Top Section)
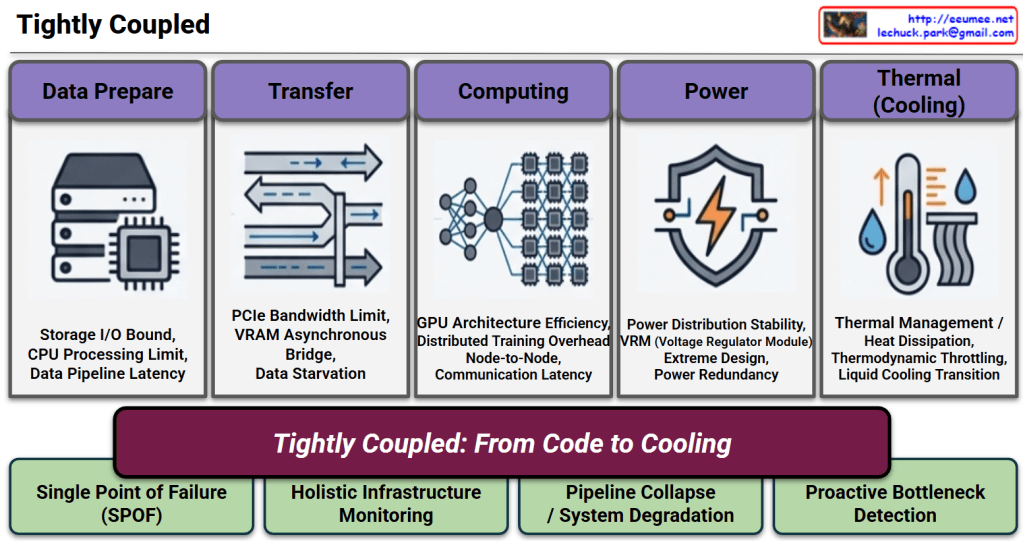
- The Flow: The diagram visualizes the critical path of an AI workload, moving sequentially through
Data Prepare➔Transfer➔Computing➔Power➔Thermal (Cooling). - The Risks: Below each pillar, specific technical bottlenecks are listed (e.g., Storage I/O Bound, PCIe Bandwidth Limit, Thermodynamic Throttling). This highlights that each stage is highly sensitive; a delay or failure in any single component can starve the GPU or cause system-wide degradation.
2. The Core Message (Center Section)
- The Banner: The central phrase, “Tightly Coupled: From Code to Cooling”, acts as the heart of the presentation. It boldly declares that AI infrastructure is no longer divided into “IT” and “Facilities.” Instead, it is a single, inextricably linked ecosystem where the execution of a single line of code directly translates to immediate physical power and cooling demands.
3. Strategic Implications & Solutions (Bottom Section)
- The Reality (Left): Because the system is so interdependent, any Single Point of Failure (SPOF) will lead to a complete Pipeline Collapse / System Degradation.
- The Operational Shift (Right): To prevent this, traditional siloed management must be replaced. The slide strongly argues for Holistic Infrastructure Monitoring and Proactive Bottleneck Detection. It visually proves that reacting to issues after they happen is too late; operations must be predictive and unified across the entire stack.
💡Summary
- Interdependence: AI data centers operate as a single, highly sensitive organism where one isolated bottleneck can collapse the entire computational pipeline.
- Paradigm Shift: The tight coupling of software workloads and physical facilities (“From Code to Cooling”) makes legacy, reactive monitoring obsolete.
- Strategic Imperative: To ensure stability and efficiency, operations must transition to holistic, proactive detection driven by intelligent, autonomous management solutions.
#AIDataCenter #TightlyCoupled #InfrastructureMonitoring #ProactiveOperations #DataCenterArchitecture #AIInfrastructure #Power #Computing #Cooling #Data #IO #Memory
With Gemini