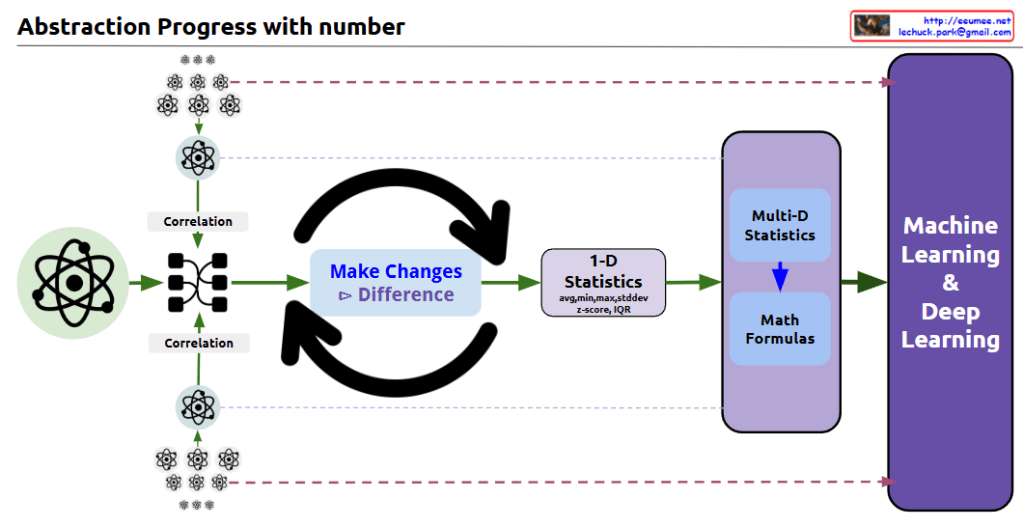
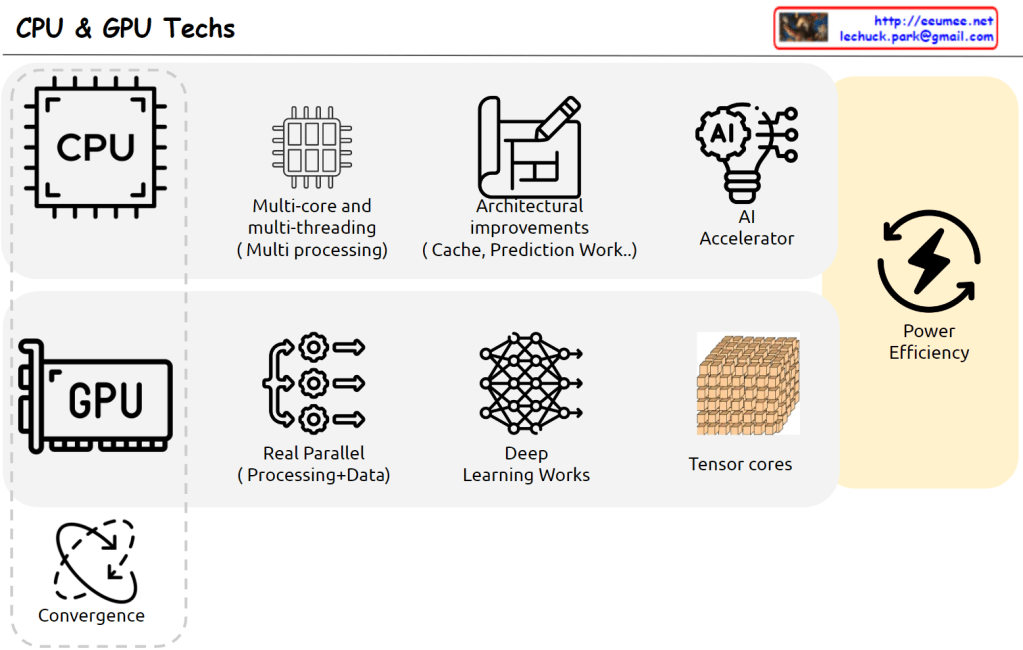
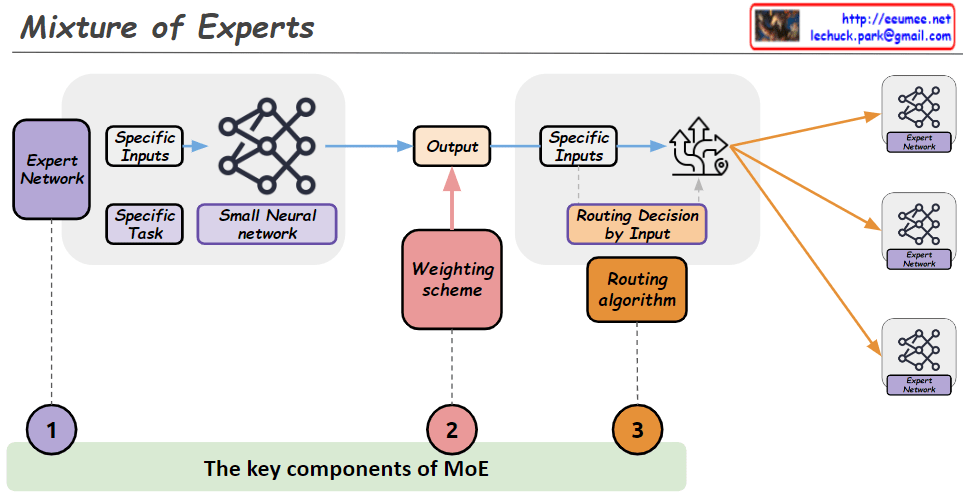
Analytical vs Empirical Approaches
Analytical Approach
- Theory Driven: Based on mathematical theories and logical reasoning
- Programmable with Design: Implemented through explicit rules and algorithms
- Sequential by CPU: Tasks are processed one at a time in sequence
- Precise & Explainable: Results are accurate and decision-making processes are transparent
Empirical Approach
- Data Driven: Based on real data and observations
- Deep Learning with Learn: Neural networks automatically learn from data
- Parallel by GPU: Multiple tasks are processed simultaneously for improved efficiency
- Approximate & Unexplainable: Results are approximations and internal workings are difficult to explain
Summary
This diagram illustrates the key differences between traditional programming methods and modern machine learning approaches. The analytical approach follows clearly defined rules designed by humans and can precisely explain results, while the empirical approach learns patterns from data and improves efficiency through parallel processing but leaves decision-making processes as a black box.
with claude