With Claude’s help
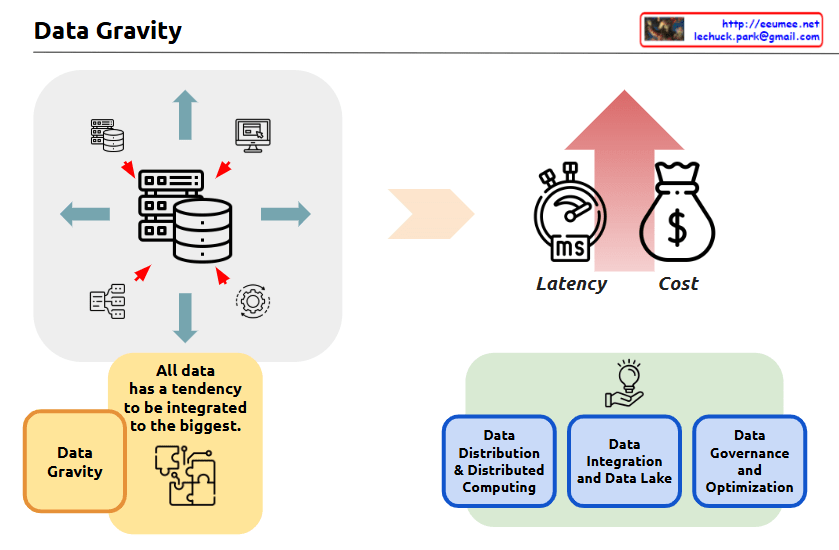
The image is titled “Data Gravity” and it appears to be an infographic or diagram that illustrates some key concepts related to data and data management.
The central part of the image shows a set of icons and arrows, depicting how “all data has a tendency to be integrated to the biggest” – this is the concept of “Data Gravity” mentioned in the title.
The image also highlights three key factors related to data:
- Latency – Represented by a stopwatch icon, indicating the time or delay factor involved in data processing and movement.
- Cost – Represented by a money bag icon, indicating the financial considerations around data management and processing.
- Data Gravity – This concept is explained in the yellow box, where it states that “all data has a tendency to be integrated to the biggest.”
The image also shows three main components related to data management:
- Data Distribution & Distributed Computing
- Data Integration and Data Lake
- Data Governance and Optimization
These three components are depicted in the bottom half of the image, illustrating the different aspects of managing and working with data.
Overall, the image seems to be providing a high-level overview of key concepts and considerations around data management, with a focus on the idea of “Data Gravity” and how it relates to factors like latency, cost, and the various data management practices.