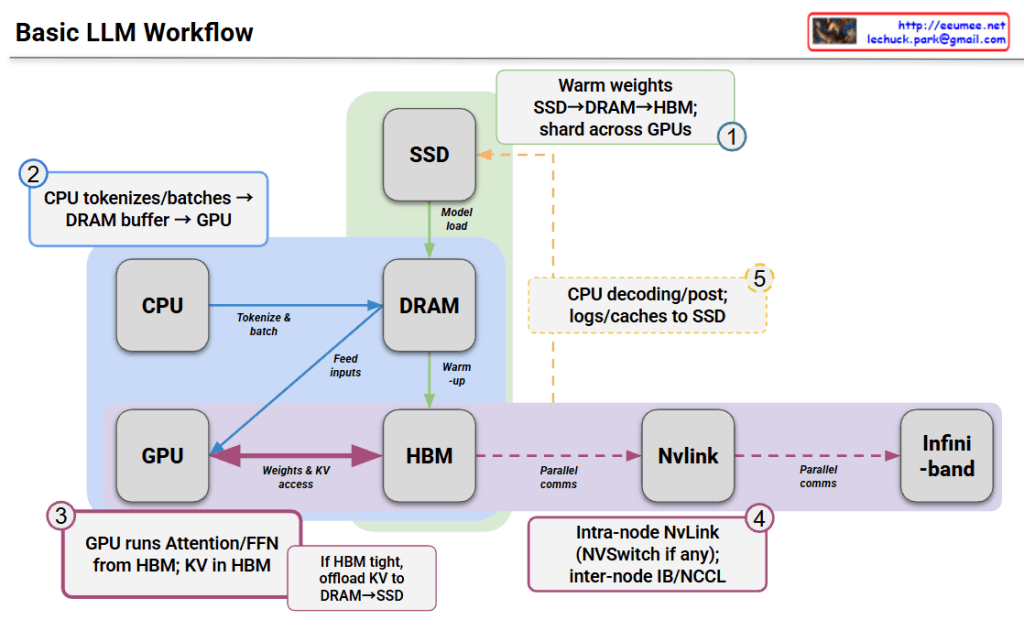
Basic LLM Workflow Interpretation
This diagram illustrates how data flows through various hardware components during the inference process of a Large Language Model (LLM).
Step-by-Step Breakdown
① Initialization Phase (Warm weights)
- Model weights are loaded from SSD → DRAM → HBM (High Bandwidth Memory)
- Weights are distributed and shared across multiple GPUs
② Input Processing (CPU tokenizes/batches)
- CPU tokenizes input text and processes batches
- Data is transferred through DRAM buffer to GPU
③ GPU Inference Execution
- GPU performs Attention and FFN (Feed-Forward Network) computations from HBM
- KV cache (Key-Value cache) is stored in HBM
- If HBM is tight, KV cache can be offloaded to DRAM or SSD
④ Distributed Communication (NvLink/Infiniband)
- Intra-node: High-speed communication between GPUs via NvLink (with NVSwitch if available)
- Inter-node: Parallel communication through InfiniBand or NCCL
⑤ Post-processing (CPU decoding/post)
- CPU decodes generated tokens and performs post-processing
- Logs and caches are saved to SSD
Key Characteristics
This architecture leverages a memory hierarchy to efficiently execute large-scale models:
- SSD: Long-term storage (slowest, largest capacity)
- DRAM: Intermediate buffer
- HBM: GPU-dedicated high-speed memory (fastest, limited capacity)
When model size exceeds GPU memory, strategies include distributing across multiple GPUs or offloading data to higher-level memory tiers.
Summary
This diagram shows how LLMs process data through a memory hierarchy (SSD→DRAM→HBM) across CPU and GPU components. The workflow involves loading model weights, tokenizing inputs on CPU, running inference on GPU with HBM, and using distributed communication (NvLink/InfiniBand) for multi-GPU setups. Memory management strategies like KV cache offloading enable efficient execution of large models that exceed single GPU capacity.
#LLM #DeepLearning #GPUComputing #MachineLearning #AIInfrastructure #NeuralNetworks #DistributedComputing #HPC #ModelOptimization #AIArchitecture #NvLink #Transformer #MLOps #AIEngineering #ComputerArchitecture
With Claude
