From Claude with some prompting
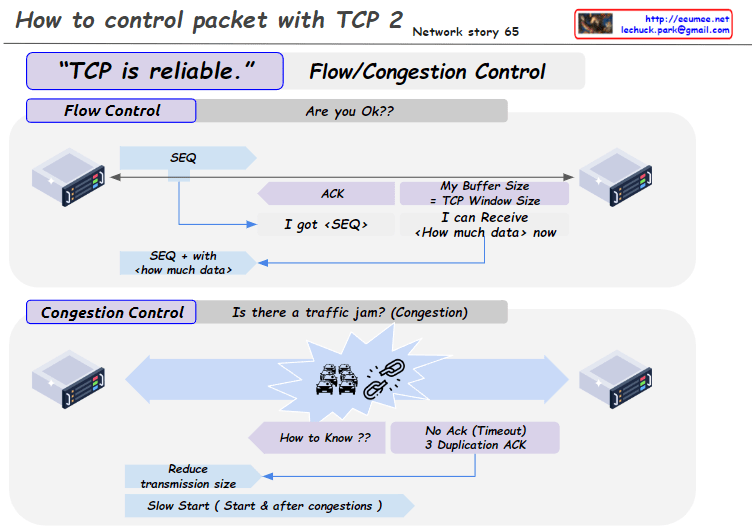
RTT is measured by sending a packet (SEQ=A) and receiving an acknowledgment (ACK), providing insights into network latency. Bandwidth is measured by sending a sequence of packets (SEQ A to Z) and observing the amount of data transferred based on the acknowledgment of the last packet.
This image explains how to measure round-trip time (RTT) and bandwidth utilization to control and optimize TCP (Transmission Control Protocol) communications. The measured metrics are leveraged by various mechanisms to improve the reliability and efficiency of TCP.
These measured metrics are utilized by several mechanisms to enhance TCP performance. TCP Timeout sets appropriate timeout values by considering RTT variation. TIMELY provides delay information to the transport layer based on RTT measurements.
Furthermore, TCP BBR (Bottleneck Bandwidth and Round-trip propagation time) models the bottleneck bandwidth and RTT propagation time to determine the optimal sending rate according to network conditions.
In summary, this image illustrates how measuring RTT and bandwidth serves as the foundation for various mechanisms that improve the reliability and efficiency of the TCP protocol by adapting to real-time network conditions.