
Outing
The Computing for the Fair Human Life.
From Claude with some prompting
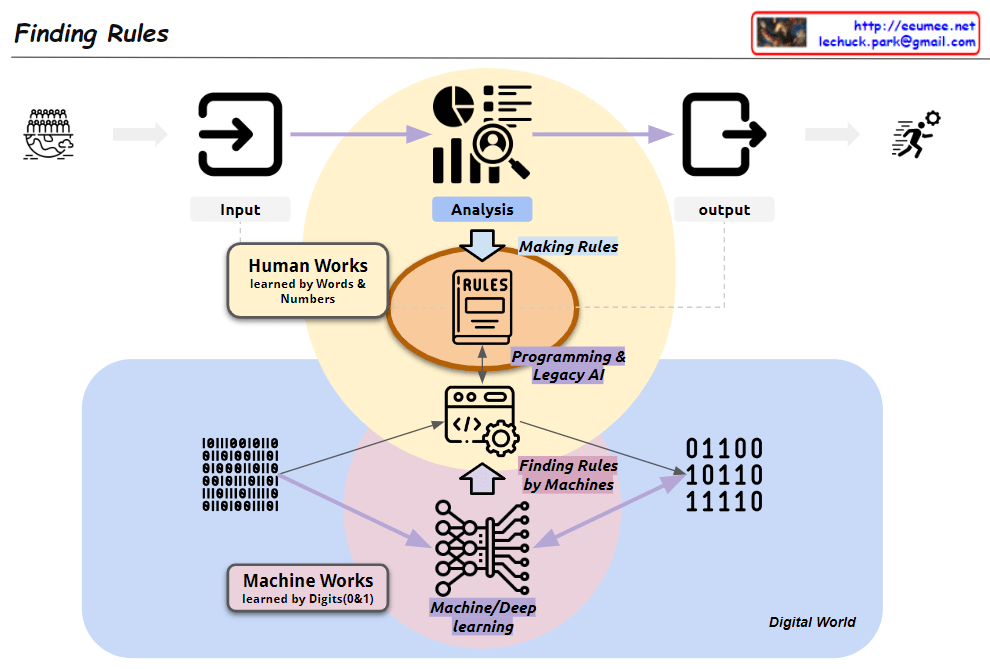
This image, titled “Finding Rules,” illustrates the contrast between two major learning paradigms:
The diagram showcases a paradigm shift:
Key components:
This visualization effectively demonstrates the evolution in data analysis and rule discovery brought about by advancements in artificial intelligence and machine learning. It highlights the shift from converting data into human-readable formats for analysis to leveraging vast amounts of binary data for machine-driven rule discovery.

From Claude with some prompting
The image depicts a diagram titled “A series of decisions,” illustrating a data processing and analysis workflow. The main stages are as follows:
Each stage is accompanied by a “Visualization” icon, indicating that data visualization plays a crucial role throughout the entire process.
At the bottom, there’s a final step labeled “Select Results with Visualization,” suggesting that the outcomes of the entire process are selected and presented through visualization techniques.
Arrows connect these stages, showing the flow from Big Data to the AI Model, with “Select Results” arrows feeding back to earlier stages, implying an iterative process.
This diagram effectively illustrates the journey from raw big data to refined AI models, emphasizing the importance of decision-making and selection at each stage of the data processing and analysis workflow.

From Claude with some prompting
This image illustrates the concept of optimization, which is achieved through a balance between stability and efficiency.
In summary, this image contrasts the differences between human and system approaches in the pursuit of optimization. By leveraging the strengths of both, the optimal balance between stability and efficiency can be achieved.
From Perplexity with some prompting
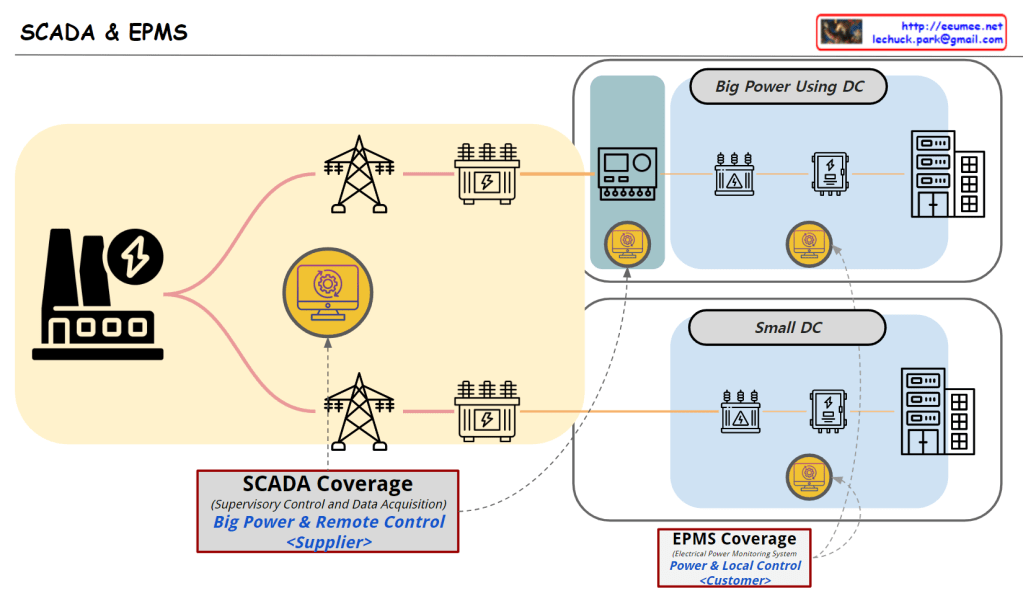
The image illustrates the roles and coverage of SCADA and EPMS systems in power management for data centers.
In conclusion, large data centers benefit from using both SCADA and EPMS to effectively manage complex power infrastructures, while small data centers typically rely on EPMS for efficient energy management.

From Claude with some prompting
This image illustrates the data processing, analysis, and machine learning application process, emphasizing how errors can be amplified at each stage:
This image effectively conveys the importance of data quality management in data science and AI fields, and the need for systematic preparation against error propagation. It highlights that as data becomes more abstracted and processed, the potential impact of early errors grows, necessitating robust error mitigation strategies throughout the data pipeline.

