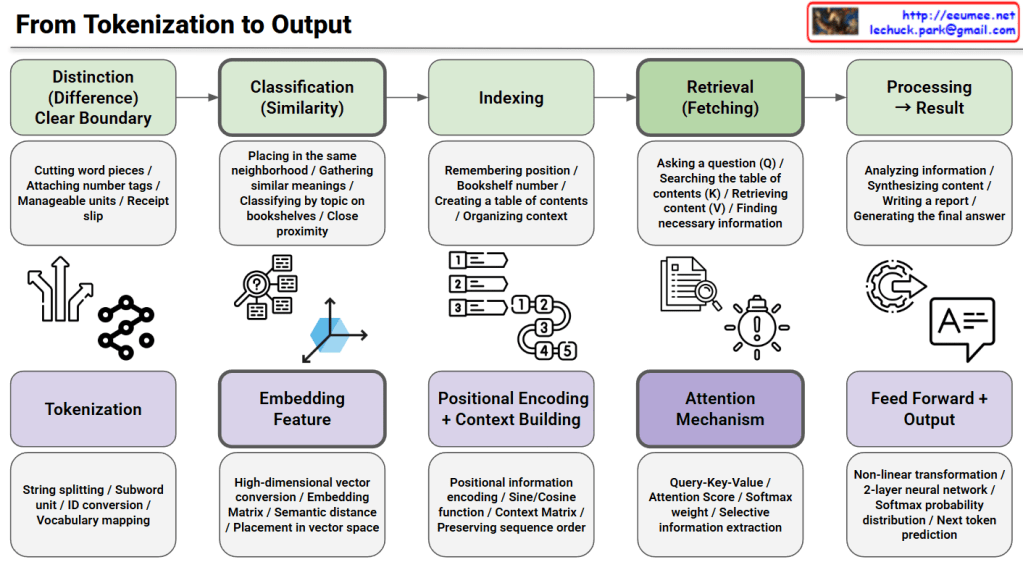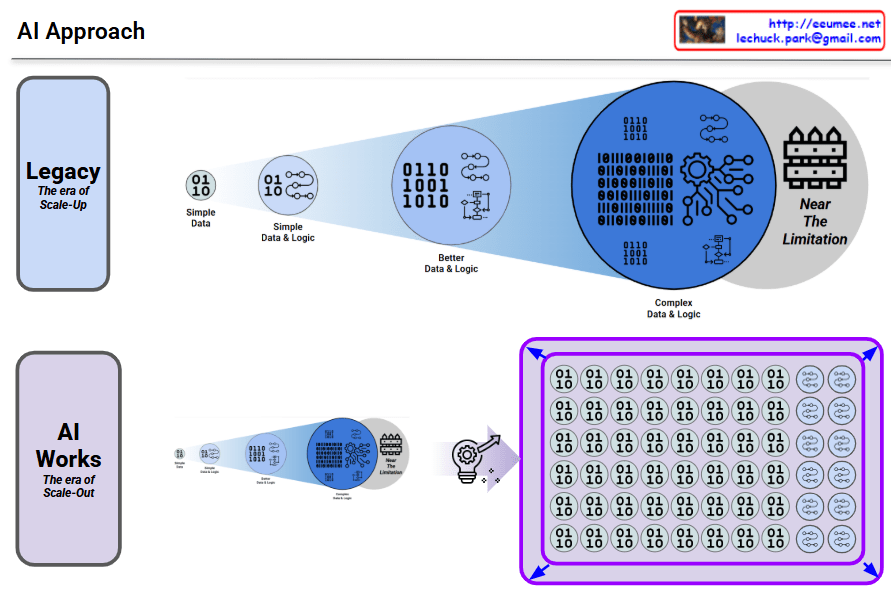
Legacy – The Era of Scale-Up
Traditional AI approach showing its limitations:
- Simple Data: Starting with basic data
- Simple Data & Logic: Combining data with logic
- Better Data & Logic: Improving data and logic
- Complex Data & Logic: Advancing to complex data and logic
- Near The Limitation: Eventually hitting a fundamental ceiling
This approach gradually increases complexity, but no matter how much it improves, it inevitably runs into fundamental scalability limitations.
AI Works – The Era of Scale-Out
Modern AI transcending the limitations of the legacy approach through a new paradigm:
- The left side shows the limitations of the old approach
- The lightbulb icon in the middle represents a paradigm shift (Breakthrough)
- The large purple box on the right demonstrates a completely different approach:
- Massive parallel processing of countless “01/10” units (neural network neurons)
- Horizontal scaling (Scale-Out) instead of sequential complexity increase
- Fundamentally overcoming the legacy limitations
Key Message
No matter how much you improve the legacy approach, there’s a ceiling. AI breaks through that ceiling with a completely different architecture.
Summary
- Legacy AI hits fundamental limits by sequentially increasing complexity (Scale-Up)
- Modern AI uses massive parallel processing architecture to transcend these limitations (Scale-Out)
- This represents a paradigm shift from incremental improvement to architectural revolution
#AI #MachineLearning #DeepLearning #NeuralNetworks #ScaleOut #Parallelization #AIRevolution #Paradigmshift #LegacyVsModern #AIArchitecture #TechEvolution #ArtificialIntelligence #ScalableAI #DistributedComputing #AIBreakthrough