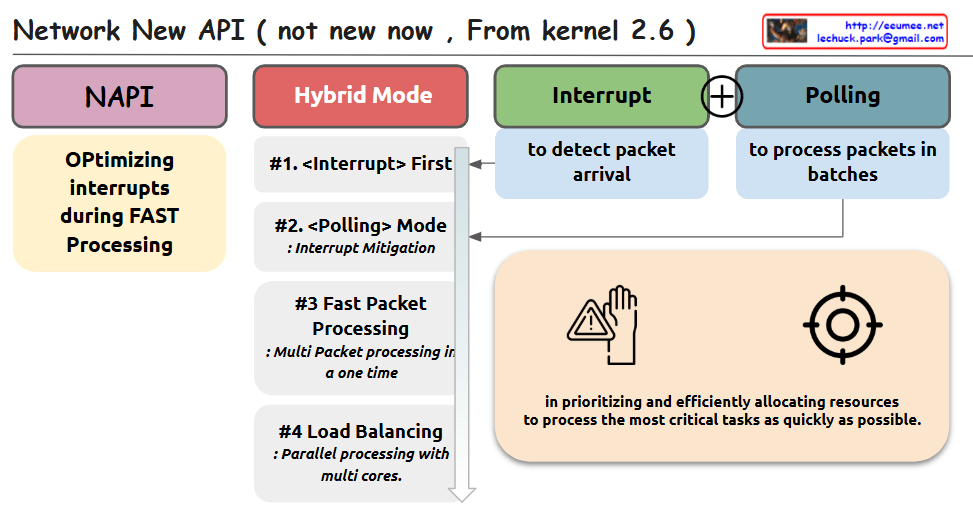
This image shows a diagram of the Network New API (NAPI) introduced in Linux kernel 2.6. The diagram outlines the key components and concepts of NAPI with the following elements:
The diagram is organized into several sections:
NAPI – The main concept is highlighted in a purple box
Hybrid Mode – In a red box, showing the combination of interrupt and polling mechanisms
Interrupt – In a green box, described as “to detect packet arrival”
Polling – In a blue box, described as “to process packets in batches”
The Hybrid Mode section details four key features:
<Interrupt> First – For initial packet detection
<Polling> Mode – For interrupt mitigation
Fast Packet Processing – For multi-packet processing in one time
Load Balancing – For parallel processing with multiple cores
On the left, there’s a yellow box explaining “Optimizing interrupts during FAST Processing”
The bottom right contains additional information about prioritizing and efficiently allocating resources to process critical tasks quickly, accompanied by warning/hand and target icons.
The diagram illustrates how NAPI combines interrupt-driven and polling mechanisms to efficiently handle network packet processing in Linux.
This image explains IO_uring, an asynchronous I/O framework for Linux. Let me break down its key components and features:
IO_uring Main Use Cases:
High-Performance Databases
High-Speed Network Applications
File Processing Systems
Core Components:
Submission Queue (SQ): Where user applications submit requests like “read this file” or “send this network packet”
Completion Queue (CQ): Where the kernel places the results after finishing a task
Shared Memory: A shared region between user space and kernel space
Key Features:
Low Latency without copying
High Throughput
Efficient Communication with the Kernel
How it Works:
Operates as an asynchronous I/O framework
User space communicates with kernel space through submission and completion queues
Uses shared memory to minimize data copying
Provides a modern interface for asynchronous I/O operations
The diagram shows the flow between user space and kernel space, with shared memory acting as an intermediary. This design allows for efficient I/O handling, particularly beneficial for applications requiring high performance and low latency.
The framework represents a significant improvement in Linux I/O handling, providing a more efficient way to handle I/O operations compared to traditional methods. It’s particularly valuable for applications that need to handle multiple I/O operations simultaneously while maintaining high performance.
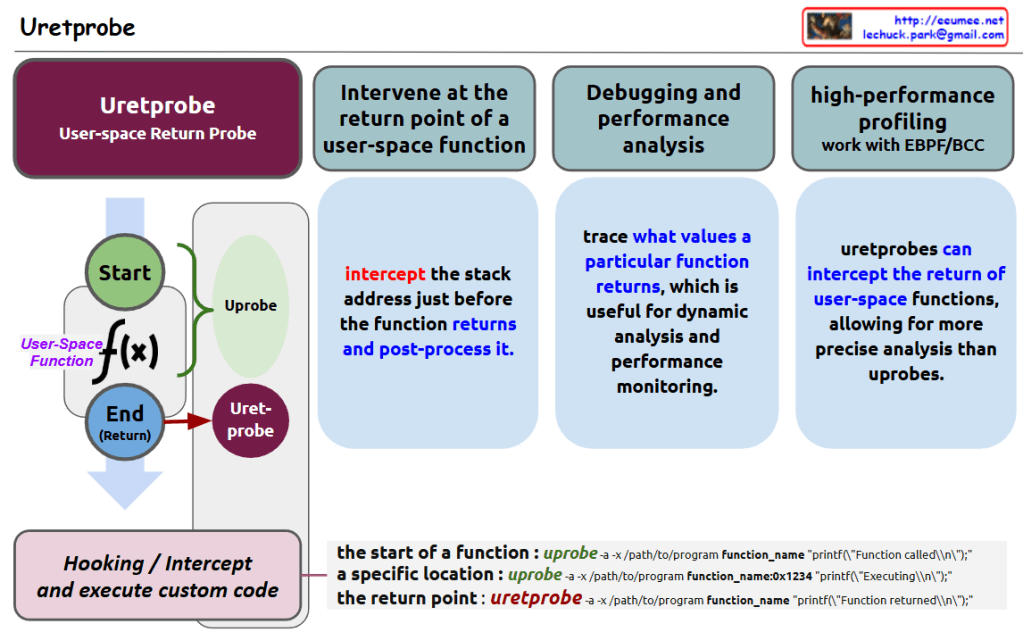
Here’s a summary of Uretprobe, a Linux kernel tracing/debugging tool:
Overview:
Uretprobe is a user-space return probe tool designed to monitor function returns in user space
It can track the execution flow from function start to end/return points
Key Features:
Ability to intervene at the return point of user-space functions
Intercepts the stack address just before function returns and enables post-processing
Supports debugging and performance analysis capabilities
Can trace specific function return values for dynamic analysis and performance monitoring
Advantages:
Provides more precise analysis compared to uprobes
Can be integrated with eBPF/BCC for high-performance profiling
The main benefit of Uretprobe lies in its ability to intercept user-space operations and perform additional code analysis, enabling deeper insights into program behavior and performance characteristics.
Similar tracing/debugging mechanisms include:
Kprobes (Kernel Probes)
Kretprobes (Kernel Return Probes)
DTrace
SystemTap
Ftrace
Perf
LTTng (Linux Trace Toolkit Next Generation)
BPF (Berkeley Packet Filter) based tools
Dynamic Probes (DynProbes)
USDT (User Statically-Defined Tracing)
These tools form part of the Linux observability and performance analysis ecosystem, each offering unique capabilities for system and application monitoring.
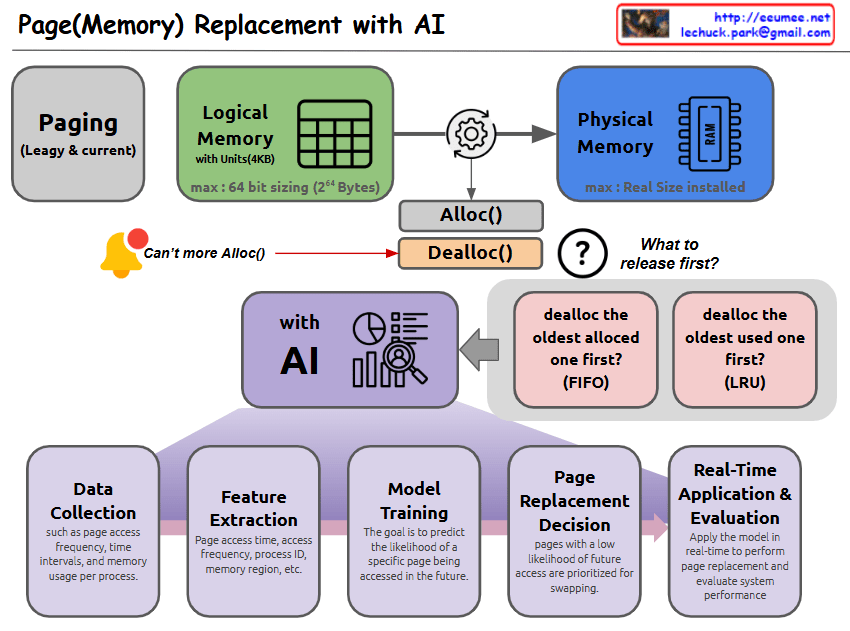
With Claude This image illustrates a Page (Memory) Replacement system using AI. Let me break down the key components:
Top Structure:
Paging (Legacy & current): Basic paging system structure
Logical Memory: Organized in 4KB units, maximum 64-bit sizing (2^64 Bytes)
Physical Memory: Limited to the actual installed memory size
Memory Allocation:
Shows Alloc() and Dealloc() functions
When no more allocation is possible, there’s a question about deallocation strategy:
FIFO (First In First Out): Deallocate the oldest allocated memory first
LRU (Least Recently Used): Deallocate the oldest used memory first
AI-based Page Replacement Process:
Data Collection: Gathers information about page access frequency, time intervals, and memory usage patterns
Feature Extraction: Analyzes page access time, access frequency, process ID, memory region, etc.
Model Training: Aims to predict the likelihood of specific pages being accessed in the future
Page Replacement Decision: Pages with a low likelihood of future access are prioritized for swapping
Real-Time Application & Evaluation: Applies the model in real-time to perform page replacement and evaluate system performance
This system integrates traditional page replacement algorithms with AI technology to achieve more efficient memory management. The use of AI helps in making more intelligent decisions about which pages to keep in memory and which to swap out, based on learned patterns and predictions.
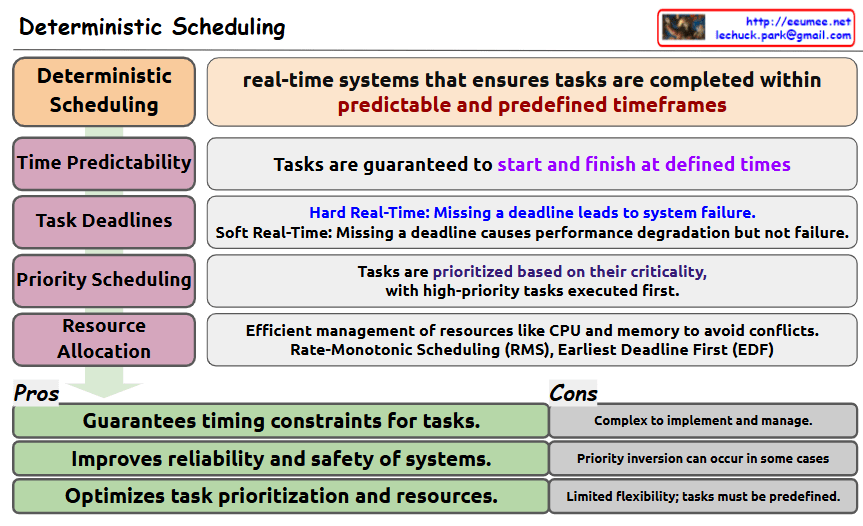
With Claude Definition: Deterministic Scheduling is a real-time systems approach that ensures tasks are completed within predictable and predefined timeframes.
Key Components:
Time Predictability
Tasks are guaranteed to start and finish at defined times
Task Deadlines
Hard Real-Time: Missing a deadline leads to system failure
Soft Real-Time: Missing a deadline causes performance degradation but not failure
Priority Scheduling
Tasks are prioritized based on their criticality
High-priority tasks are executed first
Resource Allocation
Efficient management of resources like CPU and memory to avoid conflicts
Uses Rate-Monotonic Scheduling (RMS) and Earliest Deadline First (EDF)
Advantages (Pros):
Guarantees timing constraints for tasks
Improves reliability and safety of systems
Optimizes task prioritization and resources
Disadvantages (Cons):
Complex to implement and manage
Priority inversion can occur in some cases
Limited flexibility; tasks must be predefined
The system is particularly important in real-time applications where timing and predictability are crucial for system operation. It provides a structured approach to managing tasks while ensuring they meet their specified time constraints and resource requirements.
With a Claude this image of KASLR (Kernel Address Space Layout Randomization):
Top Section:
Shows the traditional approach where the OS uses a Fixed kernel base memory address
Memory addresses are consistently located in the same position
Bottom Section:
Demonstrates the KASLR-applied approach
The OS uses Randomized kernel base memory addresses
Right Section (Components of Kernel Base Address):
“Kernel Region Code”: Area for kernel code
“Kernel Stack”: Area for kernel stack
“Virtual Memory mapping Area (vmalloc)”: Area for virtual memory mapping
“Module Area”: Where kernel modules are loaded
“Specific Memory Region”: Other specific memory regions
Booting Time:
This is when the base addresses for kernel code, data, heap, stack, etc. are determined
The main purpose of KASLR is to enhance security. By randomizing the kernel’s memory addresses, it makes it more difficult for attackers to predict specific memory locations, thus preventing buffer overflow attacks and other memory-based exploits.
The diagram effectively shows the contrast between:
The traditional fixed-address approach (using a wrench symbol)
The KASLR approach (using dice to represent randomization)
Both approaches connect to RAM, but KASLR adds an important security layer through address randomization.
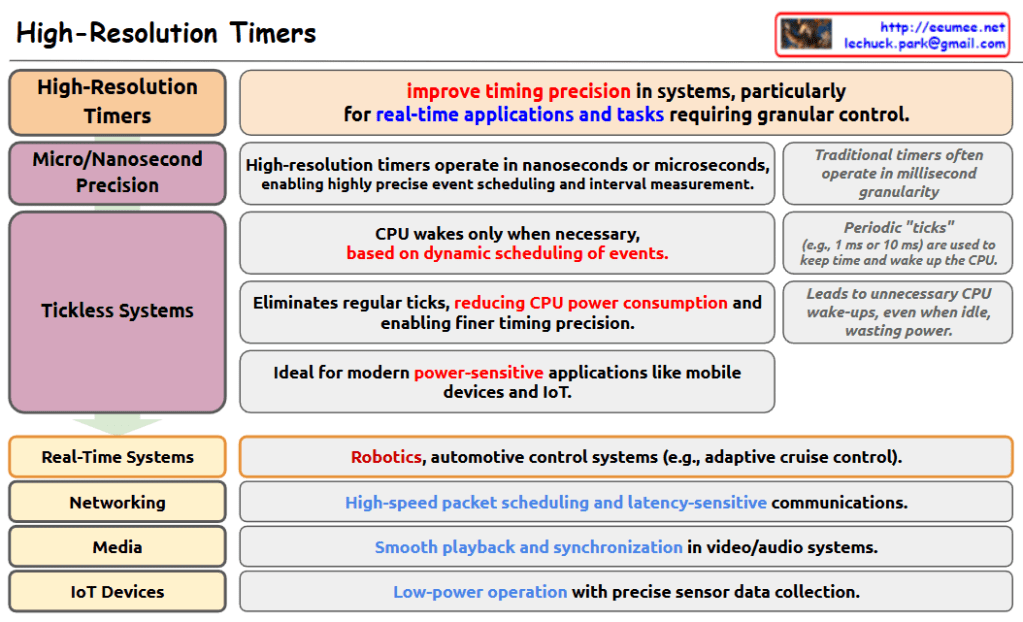
Power Efficiency: CPU activation only when necessary
Flexibility: Applicable to various fields
Reliability: Improved system reliability through accurate timing control
Future Development Directions
Optimization for IoT and mobile devices
Expanded application in industrial precision control systems
Integration with real-time data processing systems
Implementation of energy-efficient systems
This technology has evolved beyond simple time measurement to become a crucial infrastructure in modern digital systems. It serves as an essential component in implementing next-generation systems that pursue both precision and efficiency. The technology is particularly valued for achieving both power efficiency and precision, meeting various technical requirements of modern applications.
Key Features:
System timing precision improvement
Power efficiency optimization
Real-time application performance enhancement
Precise data collection and control capability
Extended battery life for IoT and mobile devices
Foundation for high-precision system operations
The high-resolution timer technology represents a fundamental advancement in system timing, enabling everything from precise scientific measurements to efficient power management in mobile devices. Its impact spans across multiple industries, making it an integral part of modern technological infrastructure.
This technology demonstrates how traditional timing systems have evolved to meet the demands of contemporary applications, particularly in areas requiring both precision and energy efficiency. Its versatility and reliability make it a cornerstone technology in the development of advanced digital systems.