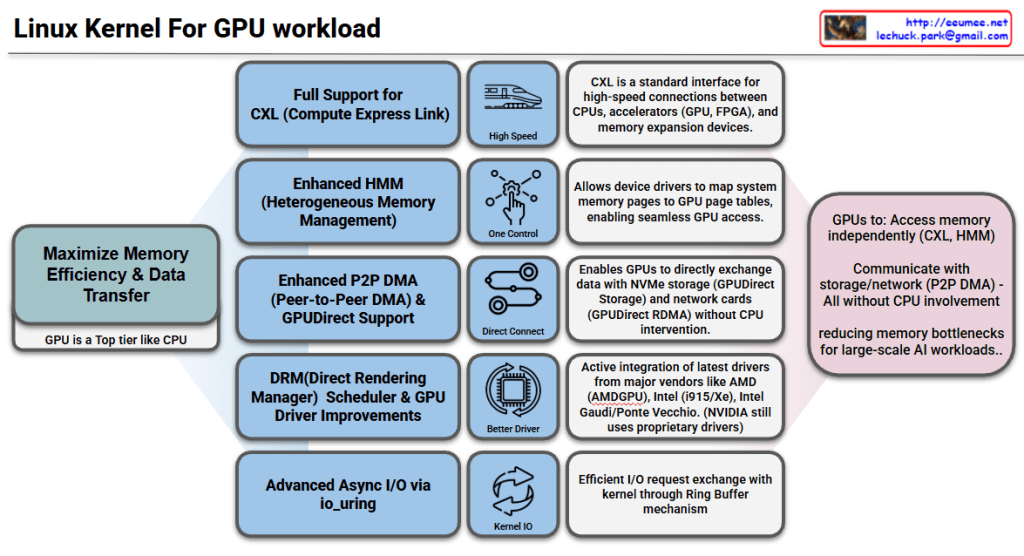
Linux Kernel GPU Workload Support Features
Goal: Maximize Memory Efficiency & Data Transfer
The core objective is to treat GPUs as a top-tier component like CPUs, reducing memory bottlenecks for large-scale AI workloads.
Key Features
1. Full CXL (Compute Express Link) Support
- Standard interface for high-speed connections between CPUs, accelerators (GPU, FPGA), and memory expansion devices
- Enables high-speed data transfer
2. Enhanced HMM (Heterogeneous Memory Management)
- Heterogeneous memory management capabilities
- Allows device drivers to map system memory pages to GPU page tables
- Enables seamless GPU memory access
3. Enhanced P2P DMA & GPUDirect Support
- Enables direct data exchange between GPUs
- Direct communication with NVMe storage and network cards (GPUDirect RDMA)
- Operates without CPU intervention for improved performance
4. DRM Scheduler & GPU Driver Improvements
- Enhanced Direct Rendering Manager scheduling functionality
- Active integration of latest drivers from major vendors: AMD (AMDGPU), Intel (i915/Xe), Intel Gaudi/Ponte Vecchio
- NVIDIA still uses proprietary drivers
5. Advanced Async I/O via io_uring
- Efficient I/O request exchange with kernel through Ring Buffer mechanism
- Optimized asynchronous I/O performance
Summary
The Linux kernel now enables GPUs to independently access memory (CXL, HMM), storage, and network resources (P2P DMA, GPUDirect) without CPU involvement. Enhanced drivers from AMD, Intel, and improved schedulers optimize GPU workload management. These features collectively eliminate CPU bottlenecks, making the kernel highly efficient for large-scale AI and HPC workloads.
#LinuxKernel #GPU #AI #HPC #CXL #HMM #GPUDirect #P2PDMA #AMDGPU #IntelGPU #MachineLearning #HighPerformanceComputing #DRM #io_uring #HeterogeneousComputing #DataCenter #CloudComputing
With Claude