
Driving
The Computing for the Fair Human Life.

This diagram illustrates network bottleneck issues in large-scale AI/ML systems.
Left side:
Center:
Right side:
The network interface specifications shown at the bottom reveal bandwidth mismatches:
A network bottleneck or failure at a specific point (marked with red circle) “spreads throughout the entire system” as indicated by the yellow arrows.
This diagram warns that in large-scale AI training, a single network bottleneck can have catastrophic effects on overall system performance. It visualizes how bandwidth imbalances at various levels – GPU-to-GPU communication, server-to-server communication, and storage access – can compromise the efficiency of the entire system. The cascading effect demonstrates how network issues can quickly propagate and impact the performance of distributed AI workloads across the infrastructure.
with Claude
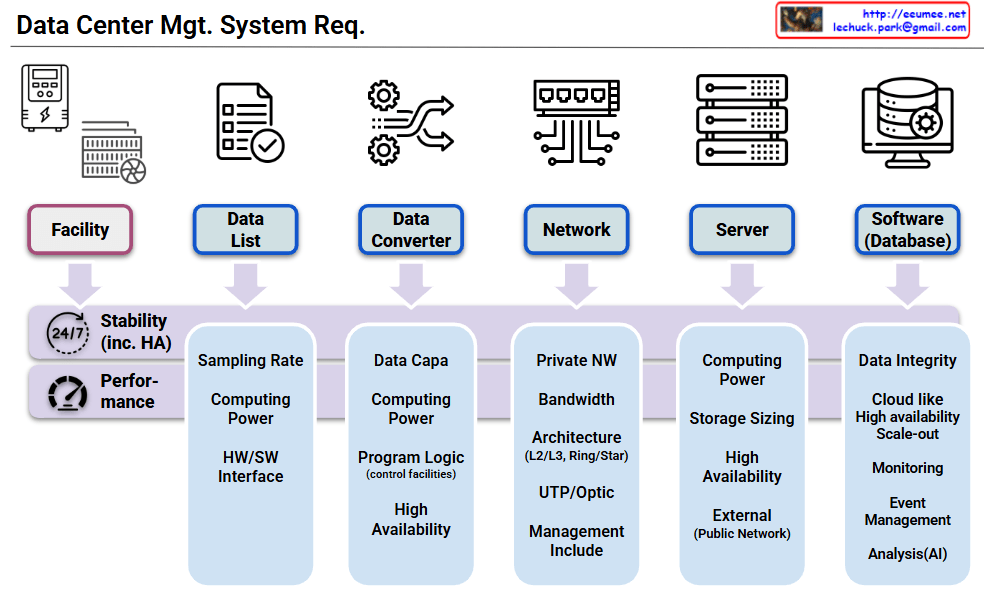
Six core components:
Fundamental requirements applied to ALL components:
This architecture emphasizes that stability and performance are fundamental prerequisites for data center operations, with each component having its own specific additional requirements built upon these two essential foundation requirements.
With Claude
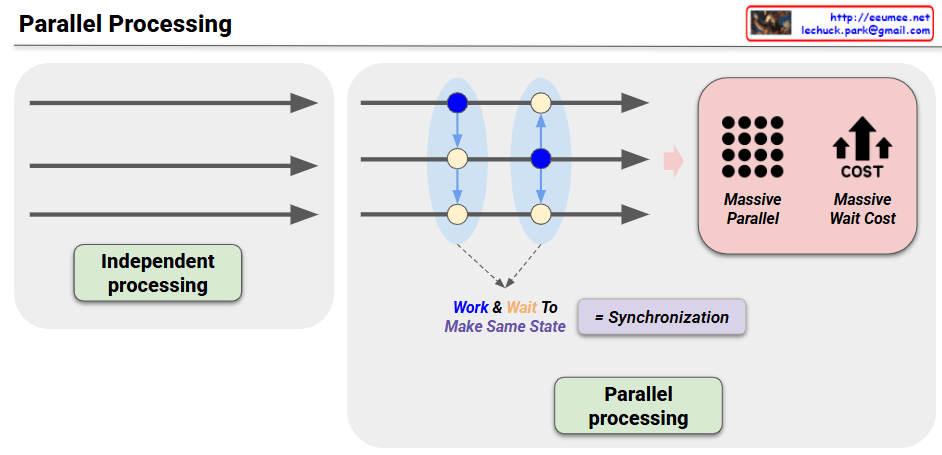
Blue Nodes (Modification Work)
Yellow Nodes (Propagation Work)
Parallel processing systems must balance performance enhancement with data consistency:
This concept is directly related to the CAP Theorem (Consistency, Availability, Partition tolerance), which is a fundamental consideration in distributed system design.
With Claude
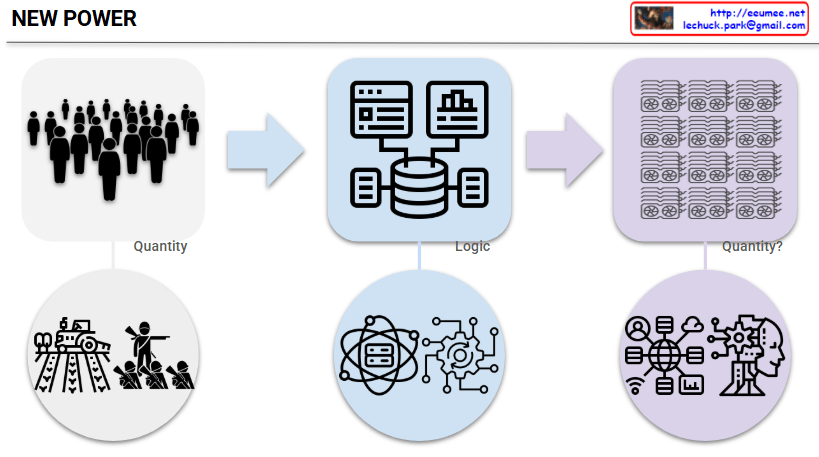
This image titled “NEW POWER” illustrates the paradigm shift in power structures in modern society.
Left Side (Past Power Structure):
Center (Transition Process):
Right Side (New Power Structure):
This diagram illustrates a fascinating return in power structures. While efficiency, innovation, and network effects – these ‘logical’ elements – were important during the digital transition period, the ‘quantitative competition’ has returned as the core with the full advent of the AI era.
In other words, rather than smart algorithms or creative ideas, how many GPUs one can secure and operate has once again become the decisive competitive advantage. Just as the number of factories and machines determined national power during the Industrial Revolution, the message suggests that we’ve entered a new era of ‘quantitative warfare’ where GPU capacity determines dominance in the AI age.
With Claude

This image visualizes the core philosophy that “In the AI era, vector-based thinking is needed rather than simplified definitions.”
Paradigm Shift in the Upper Flow:
Modern Approach in the Lower Flow:
Core Insight: In the AI era, we must move beyond simplistic definitional thinking like “an apple is a red fruit” and understand an apple as a multidimensional vector encompassing color, taste, texture, nutritional content, cultural meaning, and more. This vector-based thinking enables richer contextual understanding and flexible reasoning, allowing us to solve complex real-world problems more effectively.
Beyond simple classification or definition, this presents a new cognitive paradigm that emphasizes relationships and context. The image advocates for a fundamental shift from rigid categorical thinking to a nuanced, multidimensional understanding that better reflects how modern AI systems process and interpret information.
With Claude

