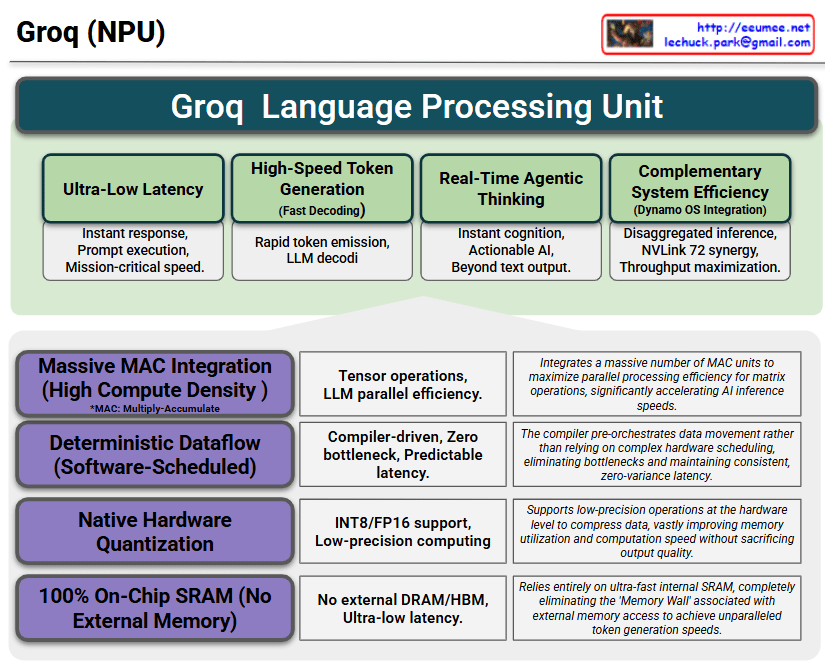
The core strength of this slide is how it connects the Capabilities/Benefits (The “What”) at the top with the Core Technologies (The “How”) at the bottom.
1. Top Section (Green): The Capabilities & Benefits of LPU
This section highlights the immediate, tangible values achieved by deploying the Groq architecture.
- Ultra-Low Latency & High-Speed Token Gen: Emphasizes the crucial need for instant response times and rapid LLM decoding for real-time services. (Note: There is a minor typo in the second box—”decodi” should be “decoding”.)
- Real-Time Agentic Thinking: Shows that this speed elevates the AI from a simple text generator to an actionable agent capable of instant cognition.
- Complementary System Efficiency: Highlights the strategic advantage of “Disaggregated Inference,” where the LPU handles fast generation while partnering with high-throughput systems (like NVLink 72) to maximize the overall data center throughput.
2. Bottom Section (Grey): The 4 Core Technologies
This section details the specific engineering choices that make the top section’s performance possible.
- Massive MAC Integration: The sheer density of compute units required for parallel tensor operations.
- Deterministic Dataflow: The software/compiler-driven approach that eliminates hardware scheduling bottlenecks, ensuring predictable, zero-variance latency.
- Native Hardware Quantization: The built-in support for low-precision formats (INT8/FP16) to speed up math and save memory.
- 100% On-Chip SRAM: The most critical differentiator—completely bypassing external memory (DRAM/HBM) to shatter the “Memory Wall.”
Summary
- Logical Architecture: The slide perfectly visualizes how four radical hardware design choices directly enable four critical performance benefits for AI inference.
- The Speed Secret: It highlights that Groq’s unprecedented speed and predictable latency come from eliminating external memory (100% SRAM) and relying on software-scheduled dataflow.
- System Synergy: It effectively positions the LPU not as a standalone replacement, but as a specialized engine for real-time agentic thinking that complements high-throughput data center systems.
#Groq #LPU #AIHardware #DataCenter #AIInference #NPU #AIAgents #DisaggregatedInference
With Gemini
