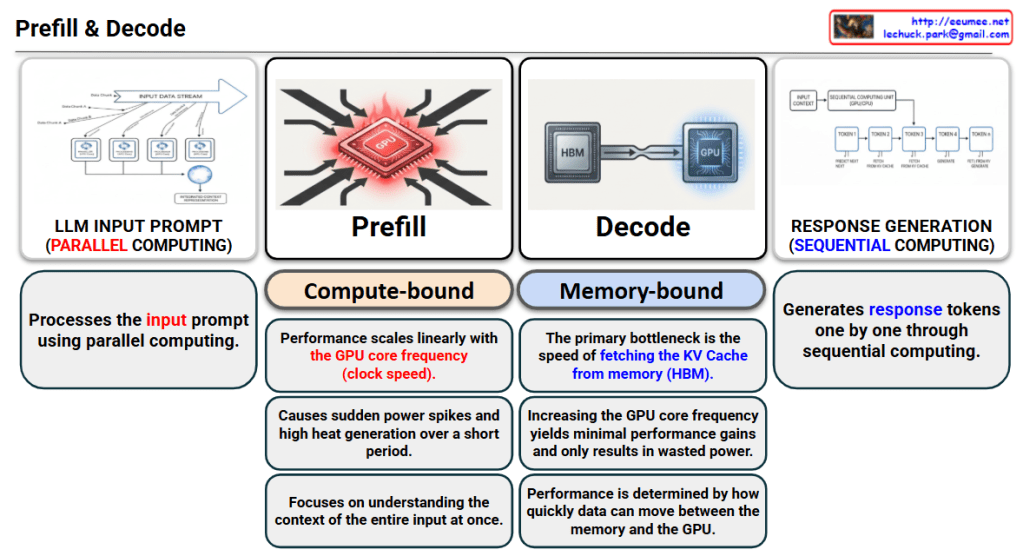
This image illustrates the dual nature of Large Language Model (LLM) inference, breaking it down into two fundamental stages: Prefill and Decode.
1. Prefill Stage: Input Processing
The Prefill stage is responsible for processing the initial input prompt provided by the user.
- Operation: It utilizes Parallel Computing to process the entire input data stream simultaneously.
- Constraint: This stage is Compute-bound.
- Performance Drivers:
- Performance scales linearly with the GPU core frequency (clock speed).
- It triggers sudden power spikes and high heat generation due to intensive processing over a short duration.
- The primary goal is to understand the context of the entire input at once.
2. Decode Stage: Response Generation
The Decode stage handles the actual generation of the response, producing one token at a time.
- Operation: it utilizes Sequential Computing, where each new token depends on the previous ones.
- Constraint: This stage is Memory-bound (specifically, memory bandwidth-bound).
- Performance Drivers:
- The main bottleneck is the speed of fetching the KV Cache from memory (HBM).
- Increasing the GPU clock speed provides minimal performance gains and often results in wasted power.
- Overall performance is determined by the data transfer speed between the memory and the GPU.
Summary
- Prefill is the “understanding” phase that processes prompts in parallel and is limited by GPU raw computing power (Compute-bound).
- Decode is the “writing” phase that generates tokens one by one and is limited by how fast data moves from memory (Memory-bound).
- Optimizing LLMs requires balancing high GPU clock speeds for input processing with high memory bandwidth for fast output generation.
#LLM #Inference #GPU #PrefillVsDecode #AIInfrastructure #DeepLearning #ComputeBound #MemoryBandwidth
With Gemini
