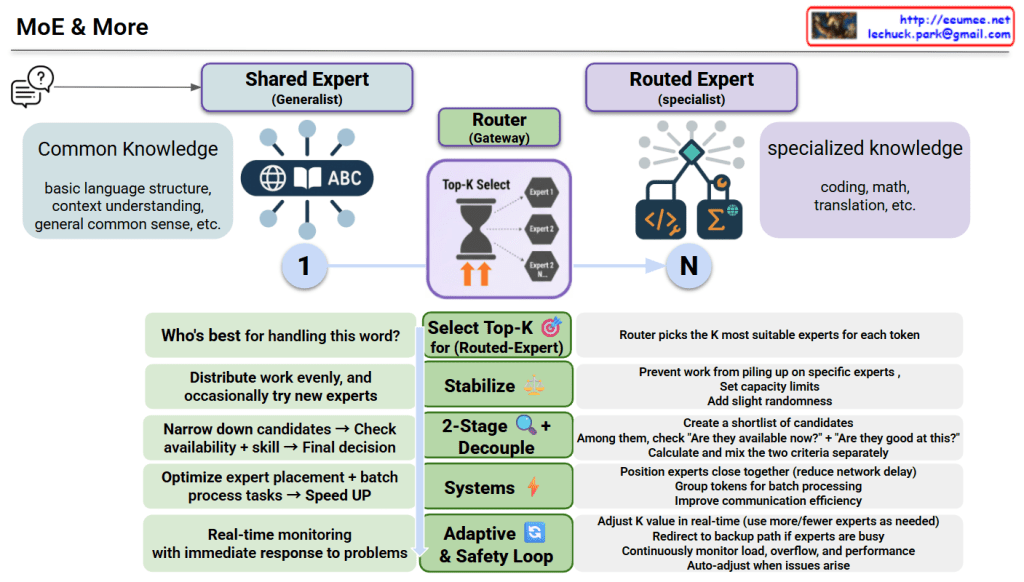
MoE & More – Architecture Interpretation
This diagram illustrates an advanced Mixture of Experts (MoE) model architecture.
Core Structure
1. Two Types of Experts
- Shared Expert (Generalist)
- Handles common knowledge: basic language structure, context understanding, general common sense
- Applied universally to all tokens
- Routed Expert (Specialist)
- Handles specialized knowledge: coding, math, translation, etc.
- Router selects the K most suitable experts for each token
2. Router (Gateway) Role
For each token, determines “Who’s best for handling this word?” by:
- Selecting K experts out of N available specialists
- Using Top-K selection mechanism
Key Optimization Techniques
Select Top-K 🎯
- Chooses K most suitable routed experts
- Distributes work evenly and occasionally tries new experts
Stabilize ⚖️
- Prevents work from piling up on specific experts
- Sets capacity limits and adds slight randomness
2-Stage Decouple 🔍
- Creates a shortlist of candidate experts
- Separately checks “Are they available now?” + “Are they good at this?”
- Calculates and mixes the two criteria separately before final decision
- Validates availability and skill before selection
Systems ⚡
- Positions experts close together (reduces network delay)
- Groups tokens for batch processing
- Improves communication efficiency
Adaptive & Safety Loop 🔄
- Adjusts K value in real-time (uses more/fewer experts as needed)
- Redirects to backup path if experts are busy
- Continuously monitors load, overflow, and performance
- Auto-adjusts when issues arise
Purpose
This system enhances both efficiency and performance through:
- Optimized expert placement
- Accelerated batch processing
- Real-time monitoring with immediate problem response
Summary
MoE & More combines generalist experts (common knowledge) with specialist experts (domain-specific skills), using an intelligent router to dynamically select the best K experts for each token. Advanced techniques like 2-stage decoupling, stabilization, and adaptive safety loops ensure optimal load balancing, prevent bottlenecks, and enable real-time adjustments for maximum efficiency. The result is a faster, more efficient, and more reliable AI system that scales intelligently.
#MixtureOfExperts #MoE #AIArchitecture #MachineLearning #DeepLearning #LLM #NeuralNetworks #AIOptimization #ScalableAI #RouterMechanism #ExpertSystems #AIEfficiency #LoadBalancing #AdaptiveAI #MLOps
With Claude
