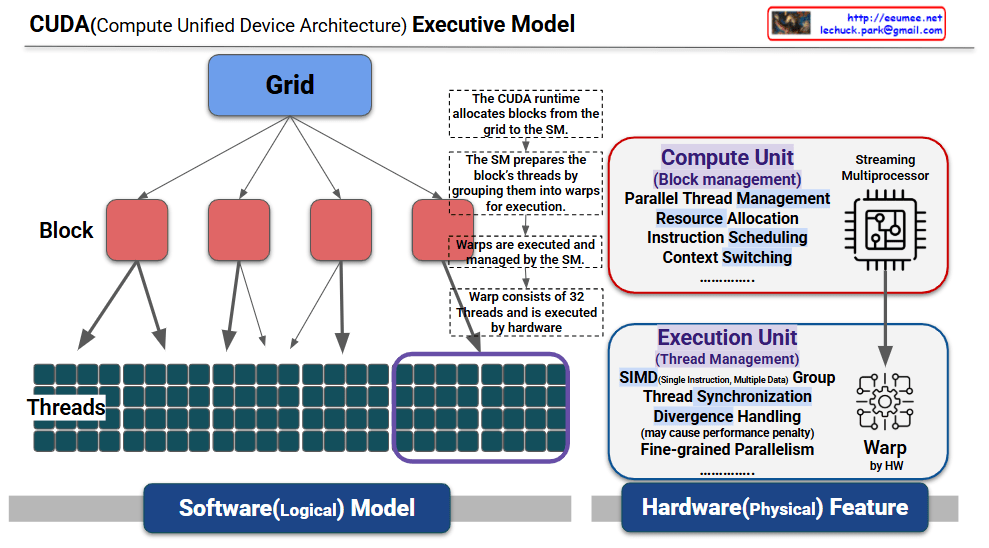
This is a structured explanation based on the provided CUDA (Compute Unified Device Architecture) execution model diagram. This diagram visually represents the relationship between the software (logical model) and hardware (physical device) layers in CUDA, illustrating the parallel processing mechanism step by step. The explanation reflects the diagram’s annotations and structure.
CUDA Executive Model Explanation
1. Software (Logical) Model
- Grid:
- The topmost layer of CUDA execution, defining the entire parallel workload. A grid consists of multiple blocks and is specified by the programmer during kernel launch (e.g.,
<<<blocksPerGrid, threadsPerBlock>>>). - Operation: The CUDA runtime allocates blocks from the grid to the Streaming Multiprocessors (SMs) on the GPU, managed dynamically by the global scheduler (e.g., GigaThread Engine). The annotation “The CUDA runtime allocates blocks from the grid to the SM, the grid prepares the block” clarifies this process.
- Block:
- Positioned below the grid, each block is a collection of threads. A block is assigned to a single SM for execution, with a maximum of 1024 threads per block (512 in some architectures).
- Preparation: The SM prepares the block by grouping its threads into warps for execution, as noted in “The SM prepares the block’s threads by grouping them into warps for execution.”
- Threads:
- The smallest execution unit within a block, with multiple threads operating in parallel. Each thread is identified by a unique thread ID (
threadIdx) and processes different data. - Grouping: The SM automatically organizes the block’s threads into warps of 32 threads each.
2. Hardware (Physical) Device
- Streaming Multiprocessor (SM):
- The core processing unit of the GPU, responsible for executing blocks. The SM performs the following roles:
- Block Management: Handles blocks allocated by the CUDA runtime.
- Parallel Thread Management: Groups threads into warps.
- Resource Allocation: Assigns resources such as registers and shared memory.
- Instruction Scheduling: Schedules warps for execution.
- Context Switching: Supports switching between multiple warps.
- Annotation: “The SM prepares the block’s threads by grouping them into warps for execution” highlights the SM’s role in thread organization.
- Warp:
- A hardware-managed execution unit consisting of 32 threads. Warps operate using the SIMT (Single Instruction, Multiple Thread) model, executing the same instruction simultaneously.
- Characteristics:
- Annotation: “Warp consists of 32 Threads and is executed by hardware” specifies the fixed warp size and hardware execution.
- The SM’s warp scheduler manages multiple warps in parallel to hide memory latency.
- Divergence: When threads within a warp follow different code paths (e.g.,
if-else), sequential execution occurs, potentially causing a performance penalty, as noted in “Divergence Handling (may cause performance penalty).” - Execution Unit:
- The hardware component that executes warps, responsible for “Thread Management.” Key functions include:
- SIMD Group: Processes multiple data with a single instruction.
- Thread Synchronization: Coordinates threads within a warp.
- Divergence Handling: Manages path divergences, which may impact performance.
- Fine-grained Parallelism: Enables high-precision parallel processing.
- Annotation: “Warps are executed and managed by the SM” indicates that the SM oversees warp execution.
3. Execution Flow
- Step 1: Block Allocation:
- The CUDA runtime dynamically allocates blocks from the grid to the SMs, as described in “The CUDA runtime allocates blocks from the grid to the SM.”
- Step 2: Thread Grouping:
- The SM groups the block’s threads into warps of 32 threads each to prepare for execution.
- Step 3: Warp Execution:
- The SM’s warp scheduler manages and executes the warps using the SIMT model, performing parallel computations. Divergence may lead to performance penalties.
4. Additional Information
- Constraints: Warps are fixed at 32 threads and executed by hardware. The number of executable blocks and warps is limited by SM resources (e.g., registers, shared memory), though specific details are omitted.
Summary
This diagram illustrates the CUDA execution model by mapping the software layers (grid → block → threads) to the hardware (SM → warp). The CUDA runtime allocates blocks from the grid to the SM, the SM groups threads into warps for execution, and warps perform parallel computations using the SIMT model.
Work with Grok
