With Claude
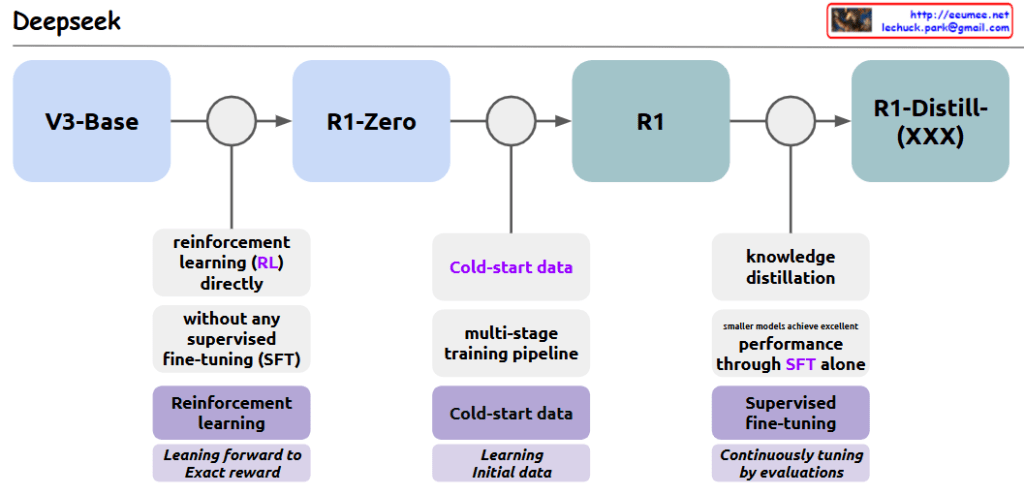
The evolution pipeline of the Deepseek model consists of three major stages:
Stage 1: V3-Base → R1-Zero
- Direct application of Reinforcement Learning (RL)
- Proceeds without Supervised Fine-tuning (SFT)
- Adopts learning approach toward exact reward
- Performs basic data classification tasks
Stage 2: R1-Zero → R1
- Utilizes cold-start data for learning
- Implements multi-stage training pipeline
- Conducts foundational learning with initial data
- Applies systematic multi-stage learning process
Stage 3: R1 → R1-Distill-(XXX)
- Model optimization through knowledge distillation
- Smaller models achieve excellent performance through SFT alone
- Continuous model tuning through evaluations
- Performance enhancement through learning with other models
This pipeline demonstrates a comprehensive approach to model development, incorporating various advanced AI training techniques and methodologies to achieve optimal performance at each stage.
