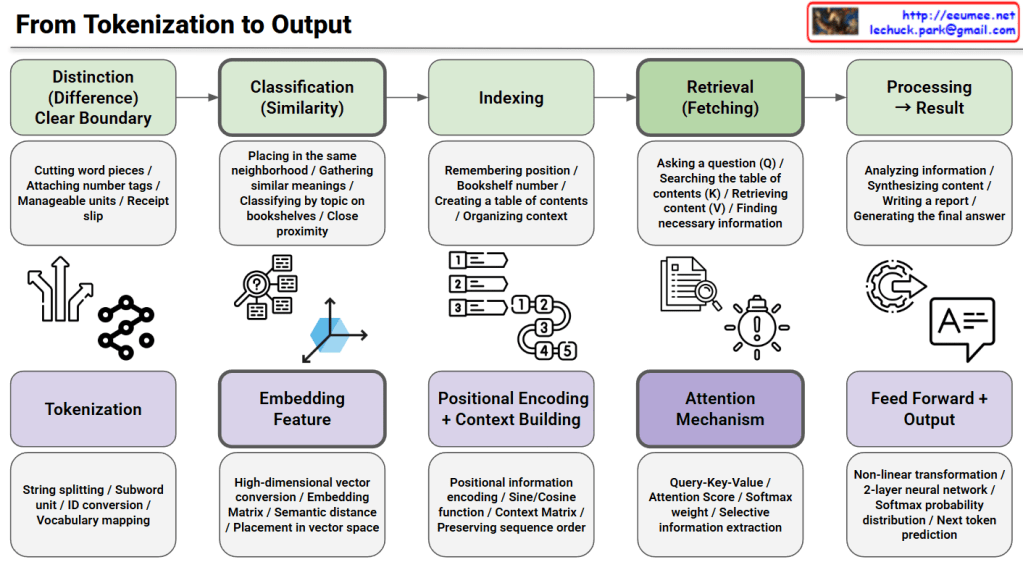
From Tokenization to Output: Understanding NLP and Transformer Models
This image illustrates the complete process from tokenization to output in Natural Language Processing (NLP) and transformer models.
Top Section: Traditional Information Retrieval Process (Green Boxes)
- Distinction (Difference) – Clear Boundary
- Cutting word pieces, attaching number tags, creating manageable units, generating receipt slips
- Classification (Similarity)
- Placing in the same neighborhood, gathering similar meanings, classifying by topic on bookshelves, organizing by close proximity
- Indexing
- Remembering position, assigning bookshelf numbers, creating a table of contents, organizing context
- Retrieval (Fetching)
- Asking a question, searching the table of contents, retrieving content, finding necessary information
- Processing → Result
- Analyzing information, synthesizing content, writing a report, generating the final answer
Bottom Section: Actual Transformer Model Implementation (Purple Boxes)
- Tokenization
- String splitting, subword units, ID conversion, vocabulary mapping
- Embedding Feature
- High-dimensional vector conversion, embedding matrix, semantic distance, placement in vector space
- Positional Encoding + Context Building
- Positional information encoding, sine/cosine functions, context matrix, preserving sequence order
- Attention Mechanism
- Query-Key-Value, attention scores, softmax weights, selective information extraction
- Feed Forward + Output
- Non-linear transformation, 2-layer neural network, softmax probability distribution, next token prediction
Key Concept
This diagram maps traditional information retrieval concepts to modern transformer architecture implementations. It visualizes how abstract concepts in the top row are realized through concrete technical implementations in the bottom row, providing an educational resource for understanding how models like GPT and BERT work internally at each stage.
Summary
This diagram explains the end-to-end pipeline of transformer models by mapping traditional information retrieval concepts (distinction, classification, indexing, retrieval, processing) to technical implementations (tokenization, embedding, positional encoding, attention mechanism, feed-forward output). The top row shows abstract conceptual stages while the bottom row reveals the actual neural network components used in models like GPT and BERT. It serves as an educational bridge between high-level understanding and low-level technical architecture.
#NLP #TransformerModels #DeepLearning #Tokenization #AttentionMechanism #MachineLearning #AI #NeuralNetworks #GPT #BERT #PositionalEncoding #Embedding #InformationRetrieval #ArtificialIntelligence #DataScience
With Claude
