

The Computing for the Fair Human Life.
with a claude’s help
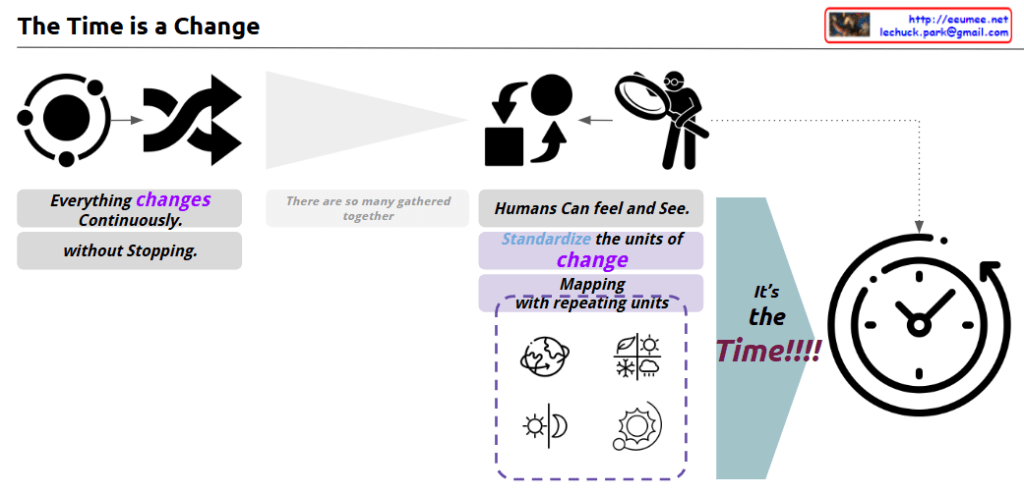
This image provides deep insights into the essence of time. The key points can be summarized as follows:
From a scientific perspective, this image explains the concept of time from multiple angles. The ceaseless change at the atomic level is a scientific fact, and the accumulation of these microscopic changes manifests as the macroscopic changes we perceive in nature. Humans have observed and measured these natural patterns of change to construct the concept of time.
However, the time units are not entirely objective. They can vary based on human physiological and cultural factors. Therefore, time can be viewed as a product of human interpretation and utilization of natural phenomena.
In summary, this image effectively illustrates the essence of the time concept from various perspectives. It shows how the changes in nature and human observation and measurement have given rise to the idea of time.

with a Claude’s help
This image provides an overview of different time series prediction methods, including their characteristics and applications. The key points are:
ARIMA (Autoregressive Integrated Moving Average):
Prophet:
LSTM (Long Short-Term Memory):
Application in a data center context:
Utilizing these prediction models can contribute to energy efficiency improvements and proactive maintenance in data centers. When selecting a prediction method, one should consider the characteristics of the data and the specific forecasting requirements.
With Claude’s help
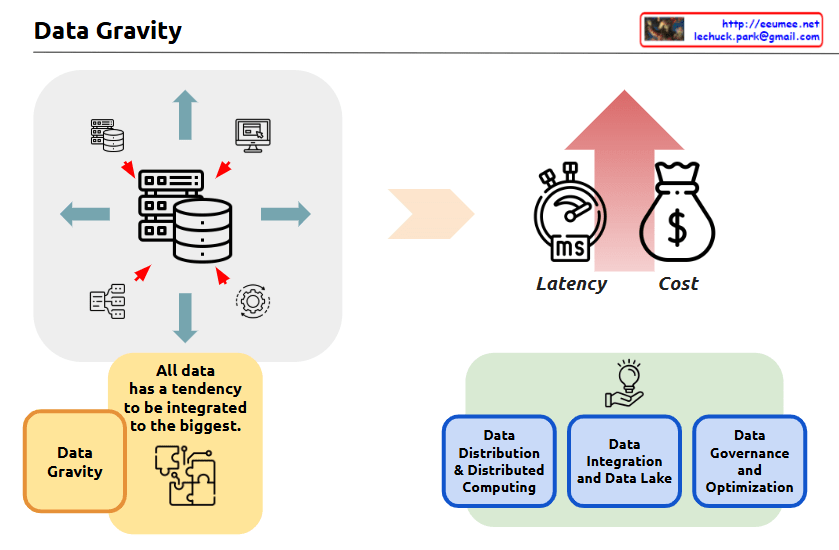
The image is titled “Data Gravity” and it appears to be an infographic or diagram that illustrates some key concepts related to data and data management.
The central part of the image shows a set of icons and arrows, depicting how “all data has a tendency to be integrated to the biggest” – this is the concept of “Data Gravity” mentioned in the title.
The image also highlights three key factors related to data:
The image also shows three main components related to data management:
These three components are depicted in the bottom half of the image, illustrating the different aspects of managing and working with data.
Overall, the image seems to be providing a high-level overview of key concepts and considerations around data management, with a focus on the idea of “Data Gravity” and how it relates to factors like latency, cost, and the various data management practices.

with a Claude’s help
The image is a diagram that explains the differences between HTTP (Hypertext Transfer Protocol) and WebSocket communication. Let me summarize the key points:
Overall, the diagram illustrates the differences between the traditional HTTP request-response model and the WebSocket communication, which provides a more efficient, real-time data transfer mechanism.
with a Claude’s help
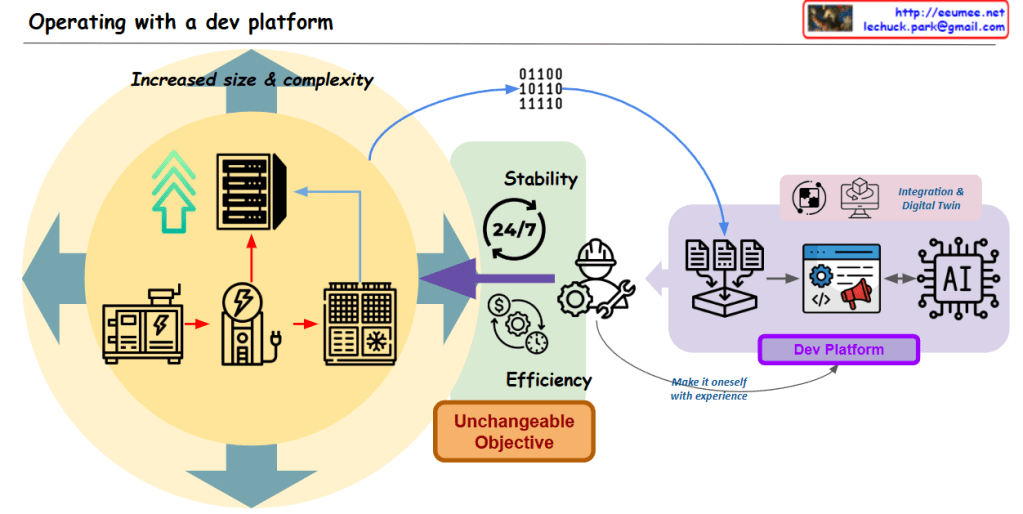
The main points covered in this image are:
In summary, this image highlights the challenges posed by the increased size and complexity of data that organizations need to manage. It presents the core operational objectives of stability, efficiency, and immutable goals, and suggests that an integrated, AI-powered development platform can help address these challenges by leveraging the synergies between data, digital technologies, and autonomous problem-solving capabilities.

Democracy and the constitution are like the fundamental principle of “1+1=10” in computer calculations. If these fundamentals are not respected, the results derived from immense computing power will ultimately be nothing more than illusions.
“1+1=10” 이어야 한다. 이 믿음이 사람들, 사회에서도 이루어지길 바란다.
물론 컴퓨터로 담아내지 못한, 또 담아낼 수도 없는 무언가 있다는 것은 잘알고 있다.
하지만, 알고 있는 것, 지켜야 하는 것, 지향해야 하는 것.. 그것은 확실히 지켜져야 한다.
정치라는 것의 아무런 관심도 없었고, 잘못된 정보로 인한 부끄러웠던 나의 과거가 존재한다. 하지만 1+1=10 이 아닌 현상을 너무 극명하게 느끼게 되면서.. 그 정치라는 것에 대해 관심을 가지게 되었다. 그리고 바랬다…누구에게나 공정한 “1+1=10” 세상이 되면 좋겠다고..
그리고 내가 그나마 알고 있는 컴퓨터 기술로 그 방향에 도움이 되면 좋겠다는 생각을 하게 된것 같다.
비트코인을 첨 알고 매력을 느꼈고. 지금은 WEB3 에 관심을 가질수 밖에 없는 이유이기도 하고.. 물론 사람의 욕심은 끝이 없고 무한할 것이다. 하지만 욕심은 문제가 아니다. 문제는 적어도 우리가 지켜온 “1+1=10” 이라는 지금까지 만들어온 기본인 Democracy 와 Constitution 은 지켜야 할 것 아닌가.. 그래야 발전을 꿈꾸고 그 위에서 사람의 욕심을 채워가야 하지 않을까 싶다.
