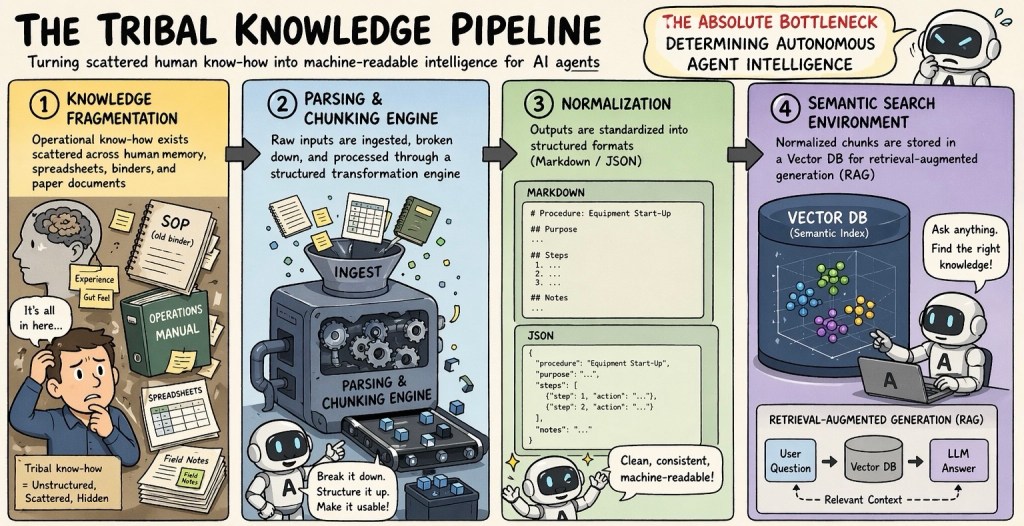
Core Summary: The Tribal Knowledge Pipeline
The absolute bottleneck for autonomous AI intelligence is the difficult process of transforming scattered, unstructured human knowledge into clean, machine-readable data.
The 4-Step Process:
- Knowledge Fragmentation: Identifying scattered operational know-how hidden in human memory, binders, and spreadsheets.
- Parsing & Chunking: Ingesting and breaking down these raw, unstructured inputs.
- Normalization: Standardizing the broken-down data into structured formats like Markdown or JSON.
- Semantic Search (RAG): Storing the normalized data in a Vector Database so the AI can accurately retrieve and use it to answer questions.
- The Ultimate Takeaway:
Converting decades of unstructured data is an extremely difficult data engineering challenge, but it is mandatory. Without this pipeline providing clean, structured context, an AI agent’s retrieval quality degrades and it cannot reason effectively.
In short: Better data in, smarter AI out.
With Claude, CahtGPT, Gemini

What’s the epistemic standard? How to filter out garbage?
LikeLike