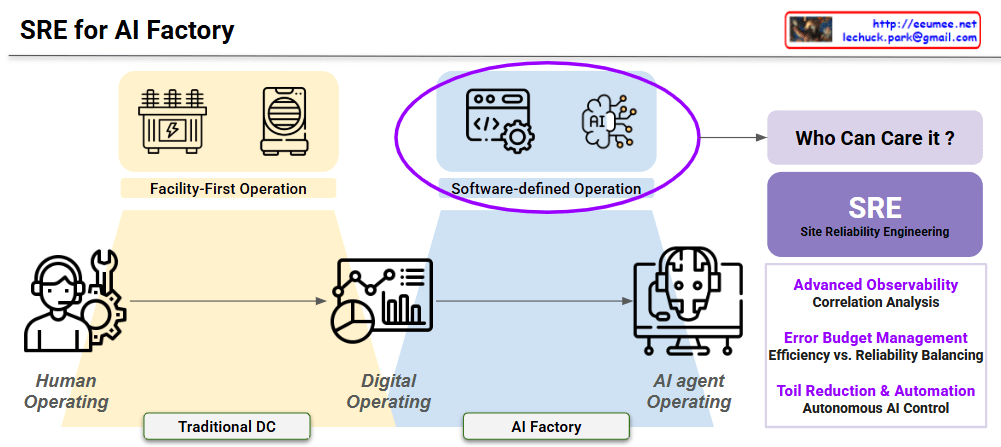
Comprehensive Image Analysis: SRE for AI Factory
1. Operational Evolution (Bottom Flow)
- Human Operating (Traditional DC): Depicts the legacy stage where manual intervention and physical inspections are the primary means of management.
- Digital Operating: A transitional phase represented by dashboards and data visualization, moving toward data-informed decision-making.
- AI Agent Operating (AI Factory): The future state where autonomous AI agents (like your AIDA platform) manage complex infrastructures with minimal human oversight.
2. Shift in Core Methodology (Top Transition)
- Facility-First Operation: Focuses on the physical health of hardware (Transformers, Cooling units) to ensure basic uptime.
- Software-Defined Operation (Highlighted): The centerpiece of the transition. It treats infrastructure as code, using software logic and AI to control physical assets dynamically.
3. The Solution: SRE (Site Reliability Engineering)
The image identifies SRE as the definitive answer to the question “Who can care for it?” by applying three technical pillars:
- Advanced Observability: Moving beyond binary alerts to deep Correlation Analysis of power and cooling data.
- Error Budget Management: Quantitatively Balancing Efficiency (PUE) vs. Reliability to push performance without risking failure.
- Toil Reduction & Automation: Achieving scalability through Autonomous AI Control, eliminating repetitive manual tasks.
3-Line Summary
- Paradigm Shift: Evolution from hardware-centric “Facility-First” management to code-driven “Software-Defined Operation.”
- The Role of SRE: Implementation of SRE principles is the essential bridge to managing the high complexity of AI Factories.
- Operational Pillars: Success relies on Advanced Observability, Error Budgeting (PUE optimization), and Toil Reduction via AI automation.
#AIFactory #SRE #SoftwareDefinedOperation #AIOps #DataCenterAutomation #Observability #InfrastructureAsCode
with Gemini
