From Claude with some prompting
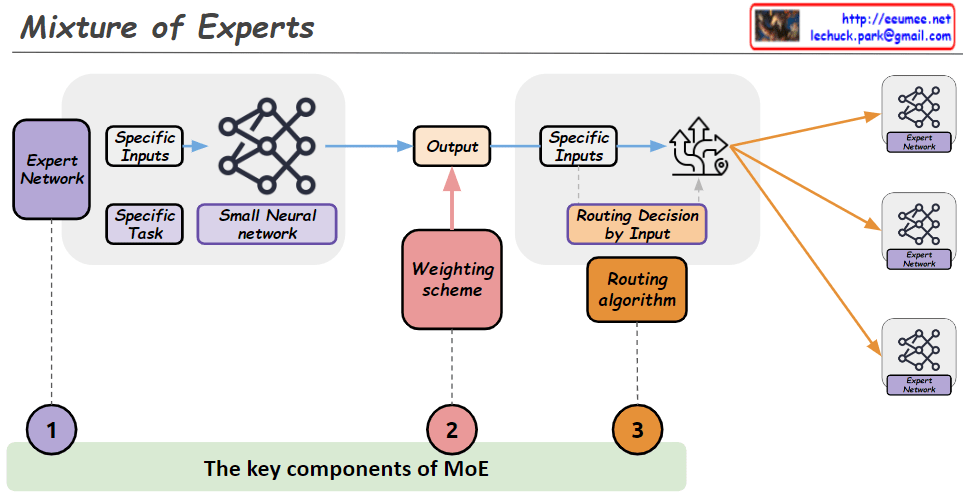
This image illustrates the key components of a Mixture of Experts (MoE) model architecture. An MoE model combines the outputs of multiple expert networks to produce a final output.
The main components are:
- Expert Network: This represents a specialized neural network trained for a specific task or inputs. Multiple expert networks can exist in the architecture.
- Weighting Scheme: This component determines how to weight and combine the outputs from the different expert networks based on the input data.
- Routing Algorithm: This algorithm decides which expert network(s) should handle a given input based on the specific inputs. It essentially routes the input data to the appropriate expert(s).
The workflow is as follows: The specific inputs are fed into the routing algorithm (3), which decides which expert network(s) should process those inputs. The selected expert network(s) (1) process the inputs and generate outputs. The weighting scheme (2) then combines these expert outputs into a final output based on a small neural network.
The key idea is that different expert networks can specialize in different types of inputs or tasks, and the MoE architecture can leverage their collective expertise by routing inputs to the appropriate experts and combining their outputs intelligently.
