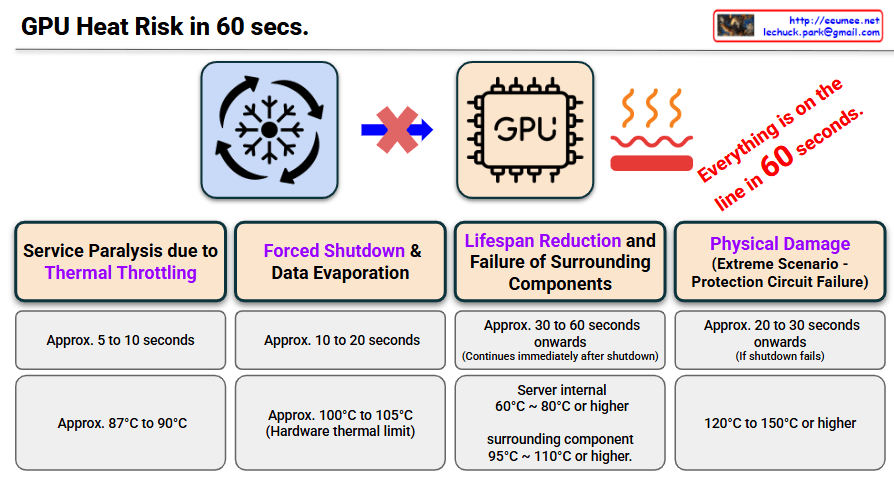
1. Intuitive Visual Context (Top Section)
- The left side depicts a scenario where a normal cooling system (fan icon) completely stops functioning, indicated by the red “X” and arrow.
- This flow visually demonstrates that the GPU chip on the right is immediately exposed to uncontrollable heat (represented by the red heat waves and the red bar at the bottom).
- The powerful slogan on the right, “Everything is on the line in 60 seconds,” serves as a stark warning that all infrastructure and data are at critical risk if no action is taken within one minute.
2. Four Critical Stages of Damage Over Time (Bottom Table)
The slide neatly structures each stage based on elapsed time and risk level. Highlighting the core damage elements in purple effectively draws the audience’s attention to the most critical impacts.
- Stage 1 (Approx. 5 to 10 seconds): Service Paralysis due to Thermal Throttling
- Temperature: Approx. 87°C to 90°C
- Impact: Due to the rapid temperature spike, the GPU automatically throttles its performance, causing immediate service paralysis.
- Stage 2 (Approx. 10 to 20 seconds): Forced Shutdown & Data Evaporation
- Temperature: Approx. 100°C to 105°C (Hardware thermal limit)
- Impact: Power is forcibly cut to protect the hardware, resulting in the permanent evaporation of unsaved checkpoint data.
- Stage 3 (Approx. 30 to 60 seconds onwards): Lifespan Reduction and Failure of Surrounding Components
- Temperature: Server internal ambient 60°C ~ 80°C+ / Surrounding components 95°C ~ 110°C+
- Impact: Even after the shutdown, massive residual heat trapped in the rack acts like an oven, severely reducing the lifespan of surrounding components (memory, cables, VRMs) and causing future failures.
- Stage 4 (Approx. 20 to 30 seconds onwards): Physical Damage (Extreme Scenario)
- Temperature: 120°C to 150°C or higher
- Impact: In the worst-case scenario where protection circuits fail, the GPU chip and board physically burn out, leading to permanent hardware destruction.
This slide clearly demonstrates that human intervention is simply too slow to stop thermal runaway in high-density environments. It provides a compelling justification for deploying an intelligent, automated solution that can monitor systems second-by-second and execute immediate emergency protocols.
- A total cooling failure in a high-density GPU environment leads to critical service throttling and data loss within a mere 10 to 20 seconds.
- Even after a forced shutdown, trapped residual heat continues to severely damage surrounding components, drastically reducing infrastructure lifespan.
- This extremely narrow 60-second window proves that human intervention is impossible, making an automated, immediate emergency response agent absolutely essential.
#DataCenter #GPU #ThermalRunaway #CoolingFailure #AIDA #DataCenterAutomation #ITInfrastructure #DisasterRecovery
With Gemini
